Build CI/CD pipelines in Azure DevOps
dbForge DevOps Automation for SQL Server is a solution designed for the management and deployment of changes to a SQL Server database. With it you can automate the deployment of database changes and build a full-cycle database CI/CD pipeline using any continuous integration or continuous deployment server that supports running PowerShell. To make getting set up easier, dbForge DevOps Automation includes plugins for Azure DevOps, TeamCity, Bamboo, and Jenkins automation servers.
dbForge DevOps Automation comes as part of the SQL Tools suite and is used in conjunction with other dbForge tools such as Unit Test, Data Generator, Data and Schema Compare, etc. dbForge DevOps Automation allows organizing a comprehensive continuous delivery pipeline for your database.
Ensure Azure DevOps Pipeline Integration
In order to seamlessly integrate dbForge SQL Tools or dbForge Studio into an Azure DevOps pipeline, it is crucial to configure the Azure DevOps agent service to operate under the user that installed and activated these tools. Additionally, it is essential to grant this user the necessary access permissions to the SQL servers involved in the continuous integration (CI) process.
How to build a CI/CD pipeline in Azure DevOps
dbForge DevOps Automation Azure DevOps plugin for SQL Server provides all the necessary features to configure the Continuous Integration process and allows you to create a database on the server, test it and deploy an artifact object.
The guide provides step-by-step procedures to create a sample Azure Pipeline application using the dbForge DevOps Automation Azure DevOps plugin for SQL Server.
Sample project
Download a sample project – DemoProject.zip – to use it in the pipeline.
Preparing the environment
To configure the CI process at Azure DevOps using the dbForge DevOps Automation for SQL Server toolset, you must first install the dbForge tools (according to your needs in the CI process) on the machine that will act as a build agent. This is usually the following set of tools:
You can install all the tools mentioned above and some more in one pack, dbForge SQL Tools.
Additionally, to organize the CI process, you’ll need:
-
A GitHub account where you can upload the sample project to the repository in order to start working with it. If you do not have it yet, create a new one for free.
-
An account at Azure DevOps. If you do not have it, follow the link, click Start Free, and follow the registration instructions.
-
The dbForge extension installed. If you already have a Dev Azure account, select Browse marketplace.
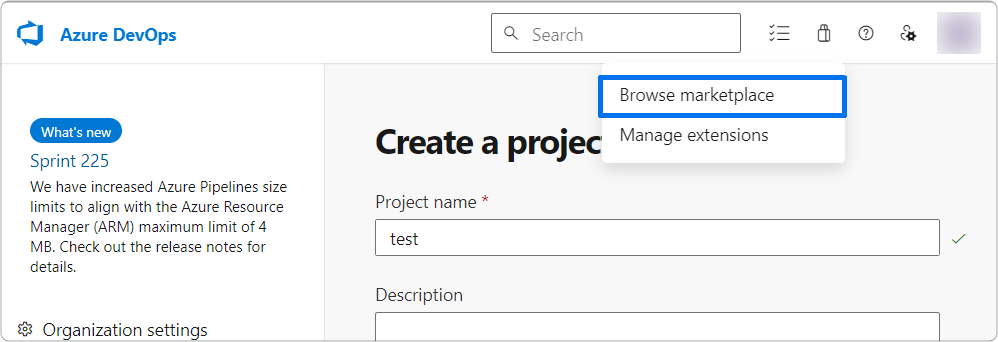
Then enter dbForge in the search box, select the dbForge extension from a list of search results, and install it.
-
A database already created on the server, as dbForge DevOps Automation does not create a new database when deploying from the scripts folder. The database may initially be empty.
Uploading a sample project to GitHub
Prior to creating a database CI pipeline, you need to upload a sample project to GitHub. To do so, download the sample project and upload it to GitHub keeping the file and folder structure unchanged.
After uploading to GitHub, the folder structure of the project will look something like this:
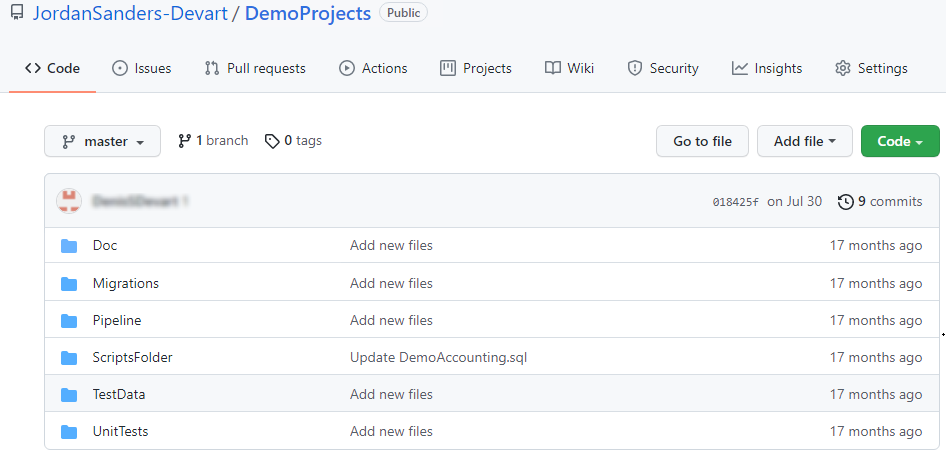
The table provides the contents of each folder :
| Folder | Description |
|---|---|
| Doc | .ddoc file to document a database. |
| Migrations | .sql files containing migration scripts to update a database. |
| ScriptsFolder | Script folder of a database. |
| TestData | DemoAccounting.dgen project file to populate a database with sample data. |
| UnitTests | .sql files containing SQL unit tests. Scripts in files can be represented by test classes and unit tests. |
Creating a database CI pipeline with dbForge extension
Upon installing the extension, you can create a Continuous Integration pipeline based on it. Creating a CI pipeline with dbForge extension is as simple as creating any other pipeline for Azure DevOps.
To do that, create a new project:
Then, name it, for example, CI Project.
Go to the Pipelines section and select the Create Pipeline option:
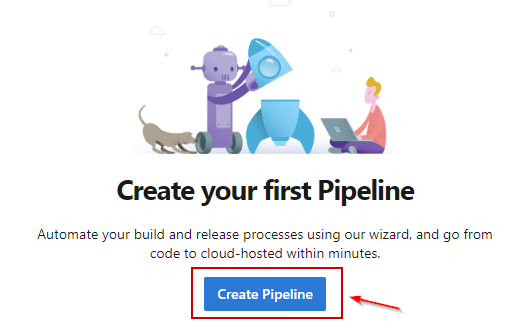
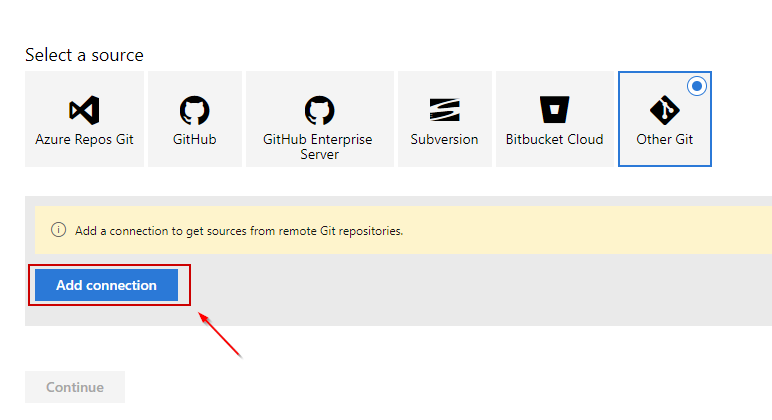
Next, in the dialog that opens, select a source repository for your project (you will get the database source code from it) and enter credentials.
In our working example, select Other Git.
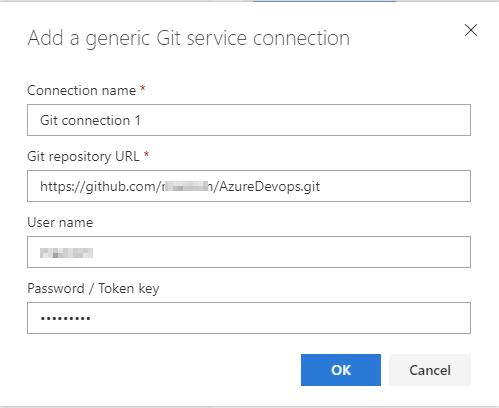
In the Select a template dialog, select Empty pipeline.
![]()
After that, in the dialog that opens, select the Default value in the drop-down list under the Agent pool option:
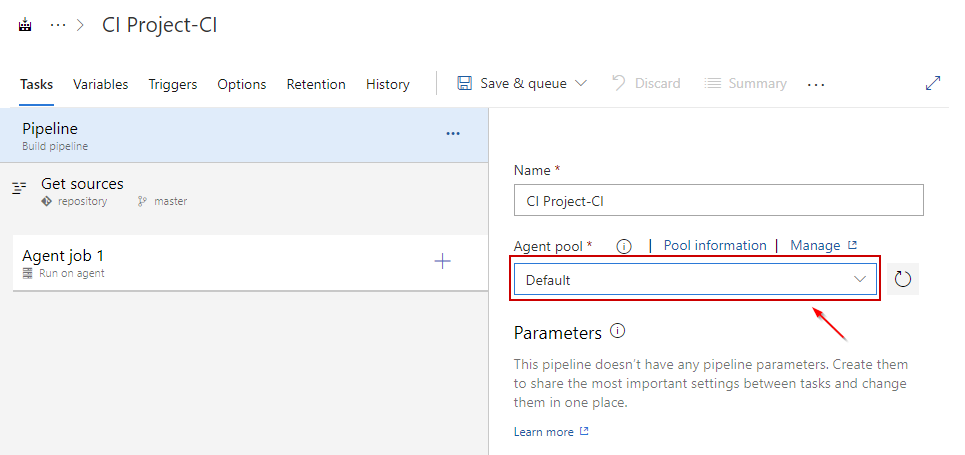
Through this process, you have created an empty Pipeline. Now you need to add dbForge tasks to it. To add tasks, click Add a task to Agent job.
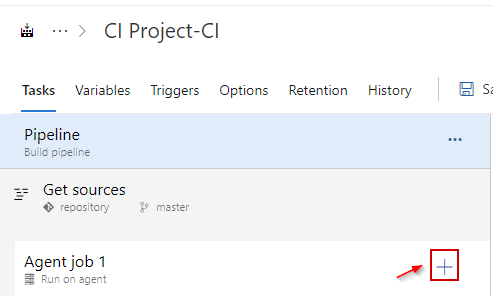
Then, enter the desired extension name - dbForge - in the search box and see the available tasks.
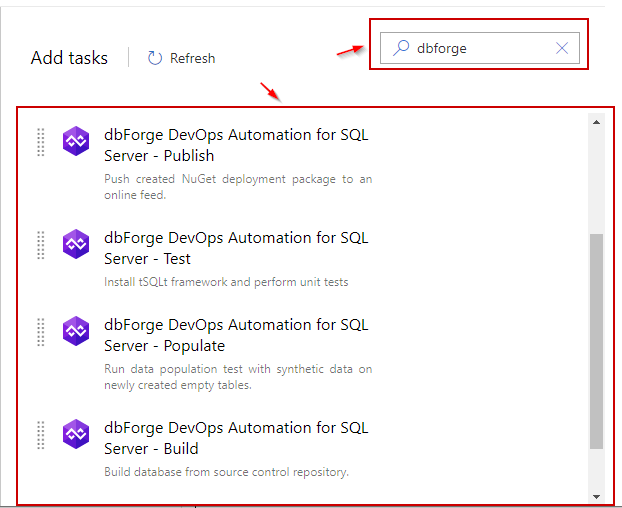
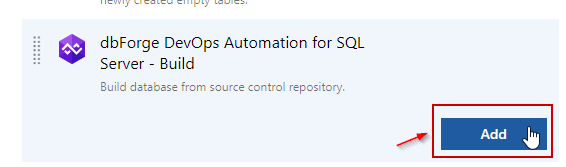
Creating the Build task
To create the Build task, select the Build step and click Add:
Then, specify the location of a Subfolder (in our case, it is ScriptsFolder) you want to restore the database from. Also, you need to configure the server name, the database name, and the connection parameters.

Verify that the settings are correct by clicking Save & queue.
Open the pipeline execution log. A green icon in the execution log indicates that the task was completed successfully.
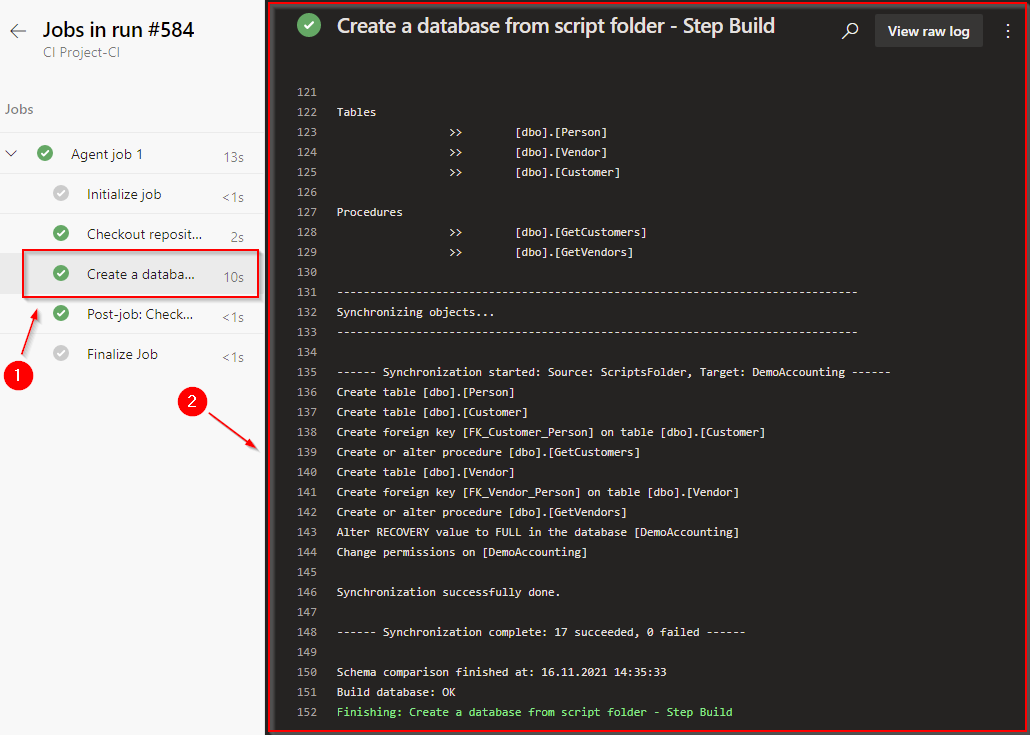
Now, in a similar way, we will add the remaining tasks to our pipeline.
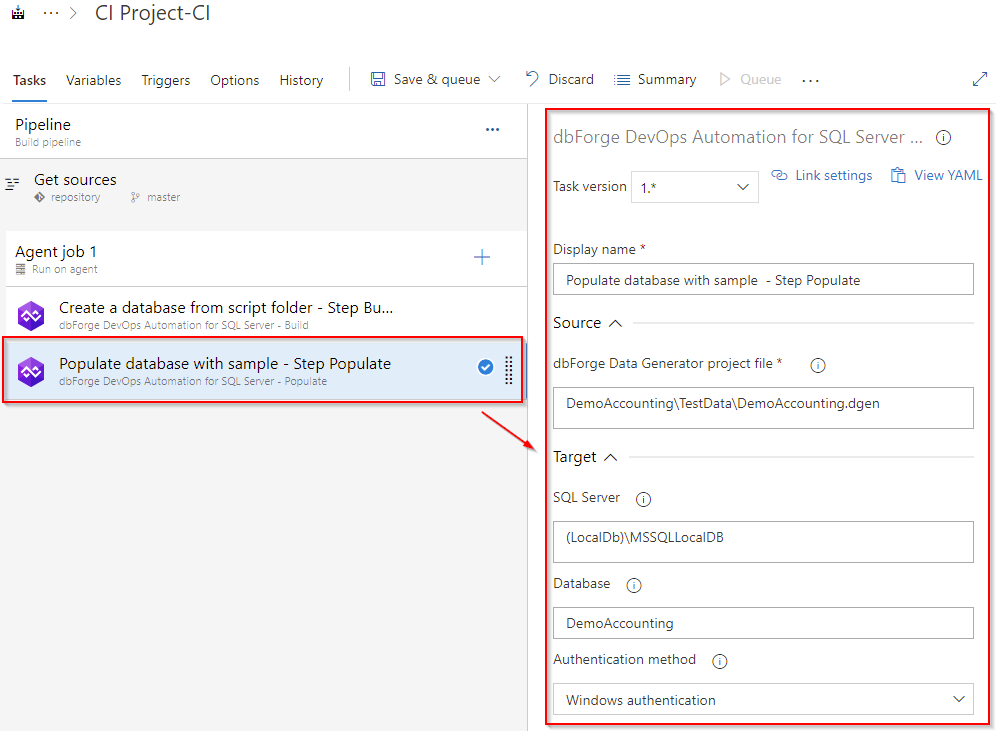
Creating the Populate task
To create the Populate task, add the dbForge DevOps Automation for SQL Server – Populate task to your pipeline. First, specify the path to the generator project. If you want to use the connection different from that indicated in the generator project file, you will need to enter the server name, database name, and the parameters for this connection. After you have configured everything, your task will look as follows.
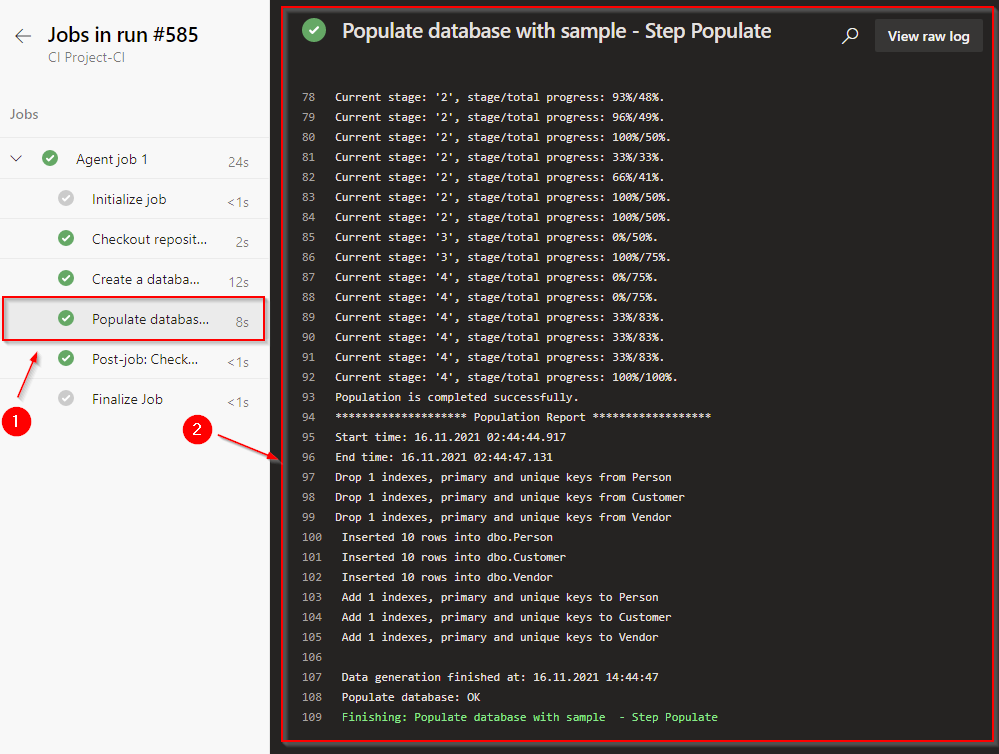
Click Save & queue to verify that your pipeline runs successfully. After the execution, open the log and check that everything is correct.
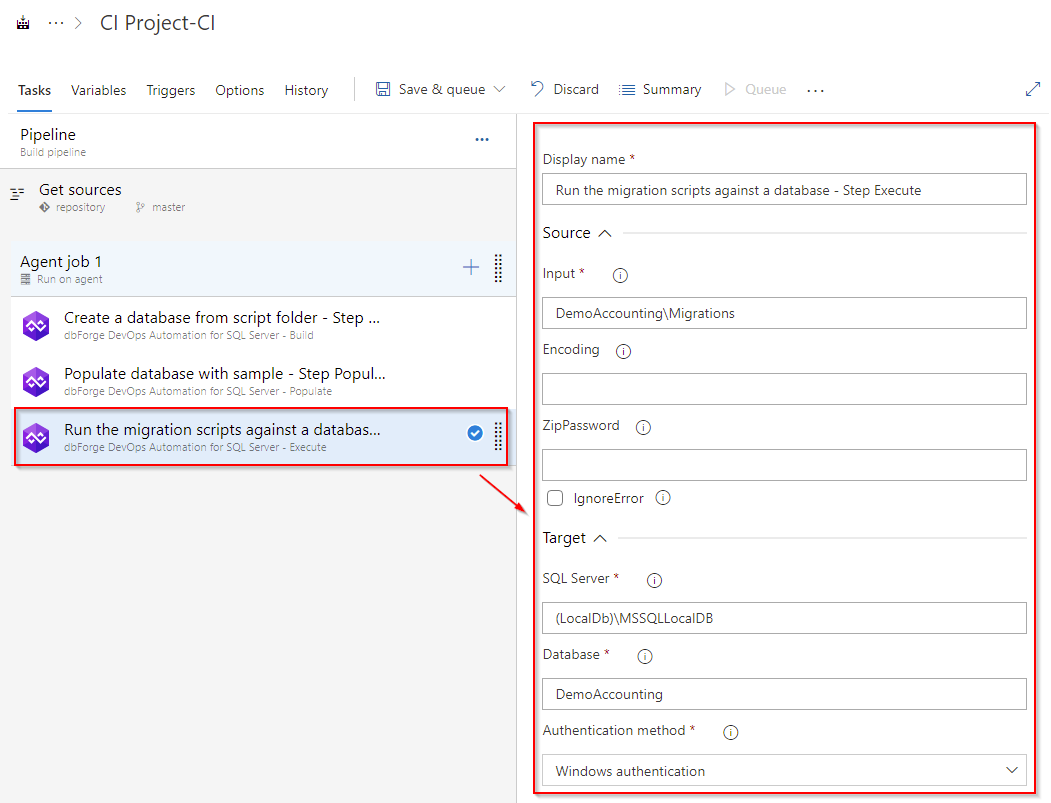
Creating the Run the migration scripts task
If you need to update the database with migration scripts, use the dbForge DevOps Automation for SQL Server – Execute task. When configuring the Execute task, specify the folder that stores the update scripts:
After execution, view the log to verify that everything was configured correctly:
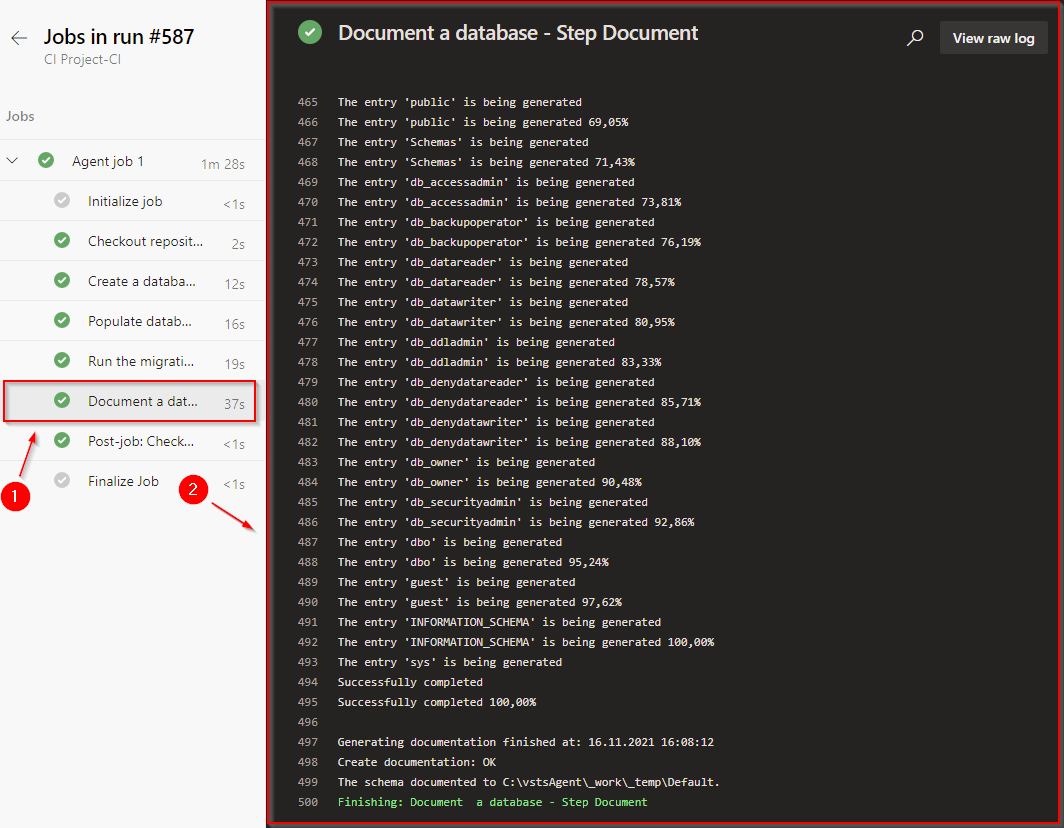
Creating the Document task
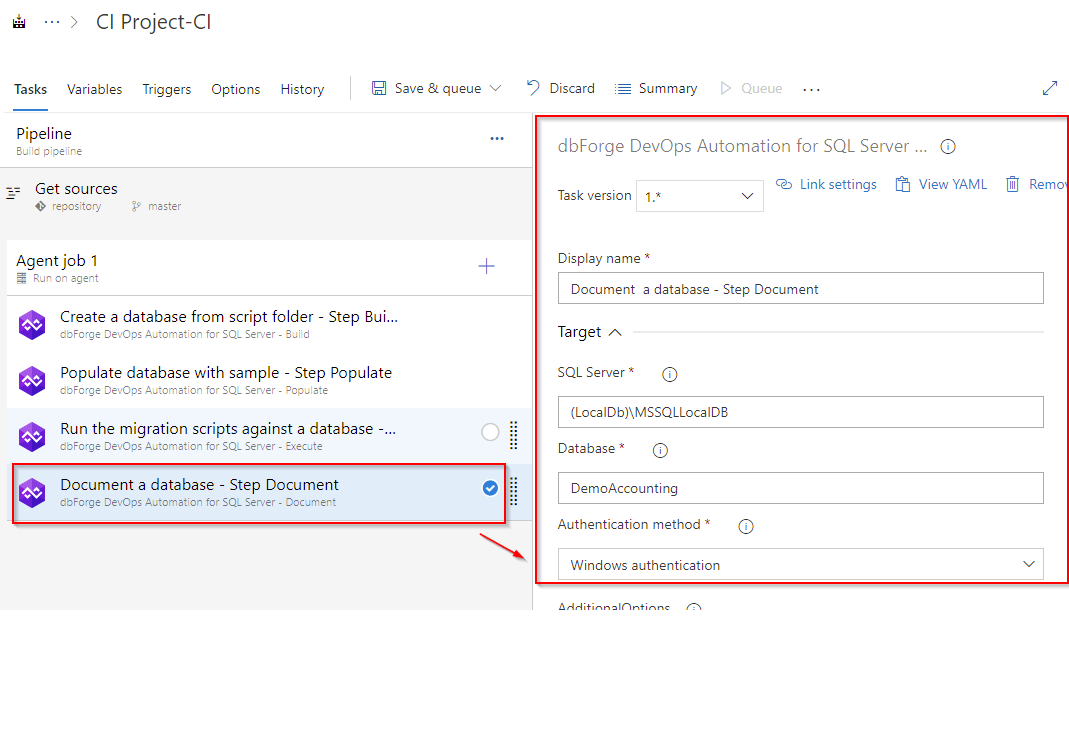
To create the Document task, add the dbForge DevOps Automation for SQL Server – Document task to the pipeline:
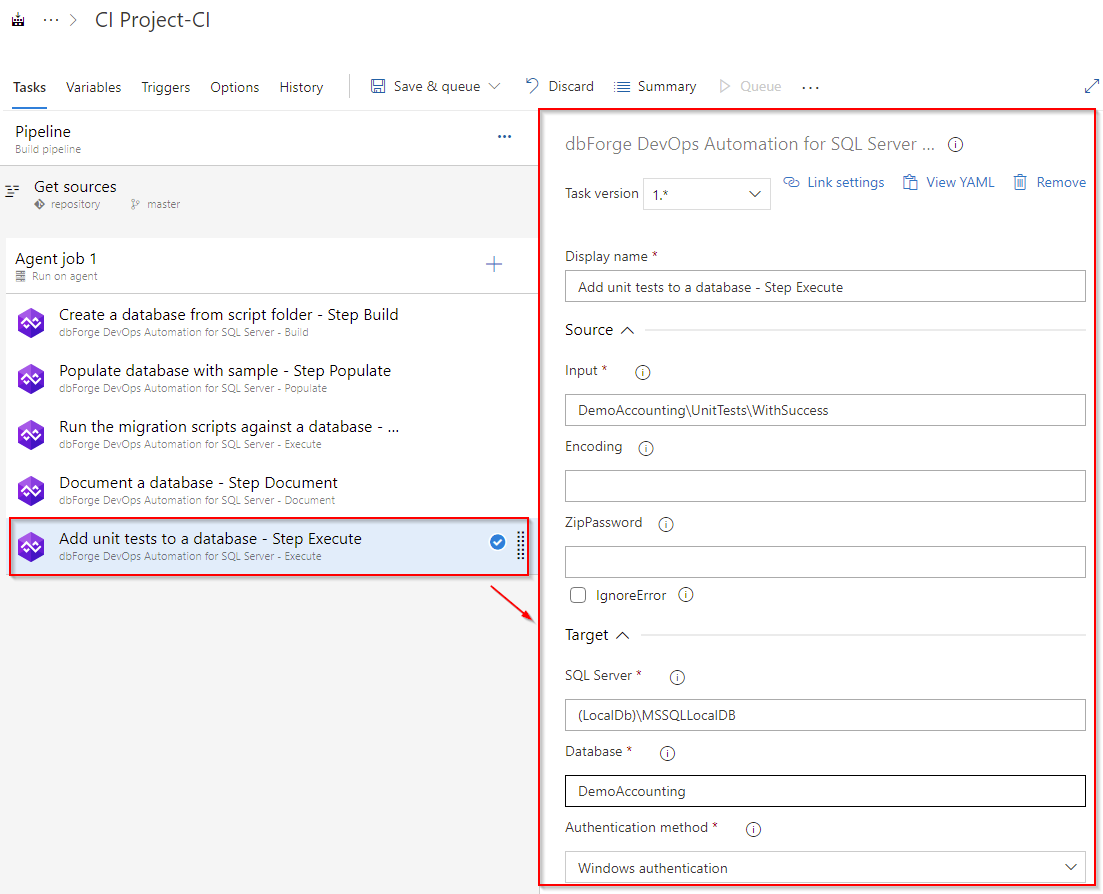
Creating the Add unit tests to a database task
Before running unit tests, you need to add them to the database. In fact, unit tests comprise conventional SQL scripts. They are stored separately from the database. To add unit tests to the database, you will need the dbForge DevOps Automation for SQL Server – Execute task, that executes SQL scripts from a folder or a file. Add the task and configure it:
Creating the Test task
To create the Test task, add the dbForge DevOps Automation for SQL Server – Test task, as you have done it with the Build, Populate, and Execute (Add unit tests to a database) tasks.
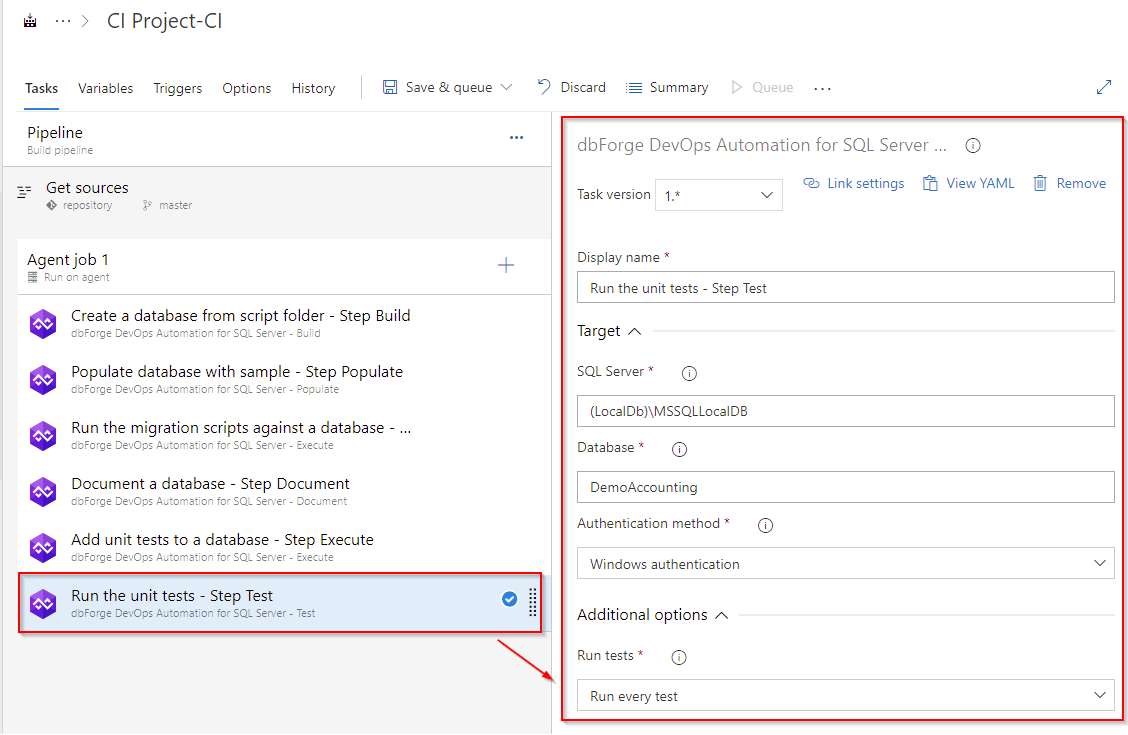
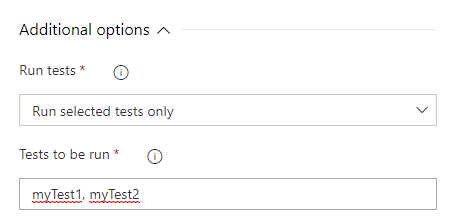
As you can see, we have specified the connection and selected the Run every test option. If you want to specify the exact tests to be run, you will need to list them with a comma:
Creating the Package task
Having created the database and tested it with the help of unit tests, you need to package the scripts folder and publish it (either on a local server or a NuGet Server).
Before deploying the finished package you need to create it. To create the Package task, add the dbForge DevOps Automation for SQL Server – Package task that will pack your scripts folder into a package:
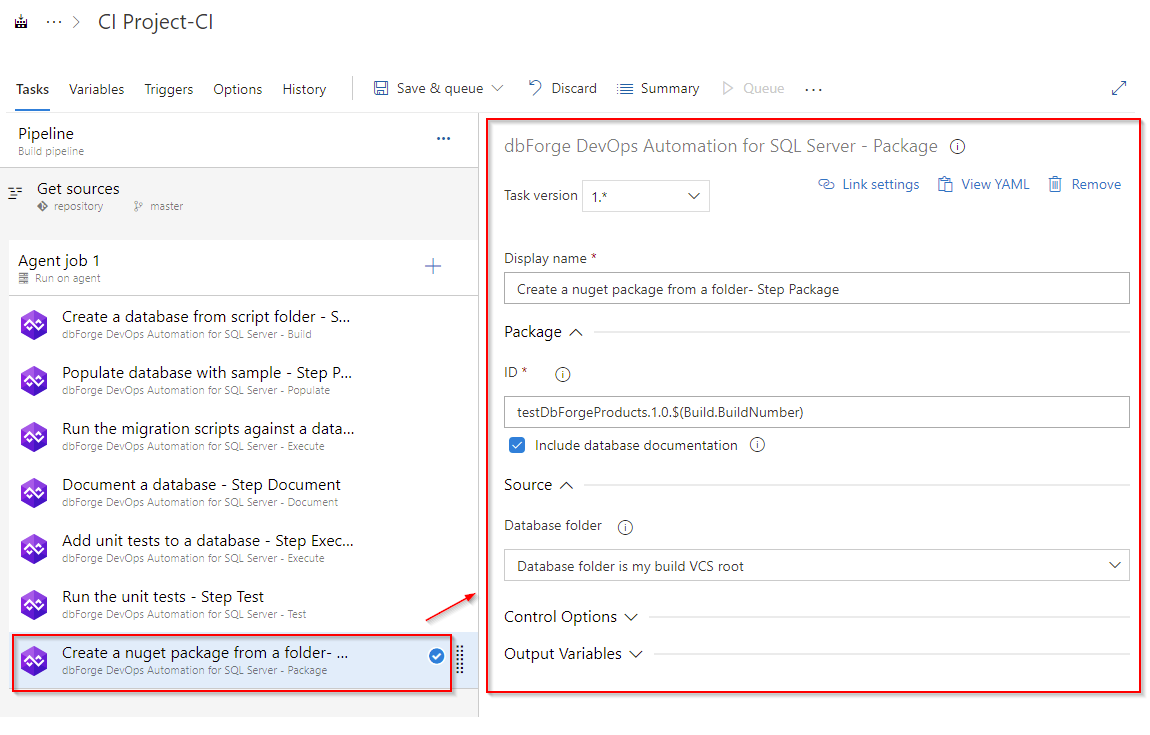
As you can see, the file name is tied to the build number and is generated dynamically according to the template. The output file will be saved to the working folder of the agent.
The generated NuGet package is an intermediate package and should be published somewhere.
Creating the Publish task
The Publish task will use the package file generated in the Package step as input. As you can see these two tasks have the same file name template. The Publish task settings are shown below.
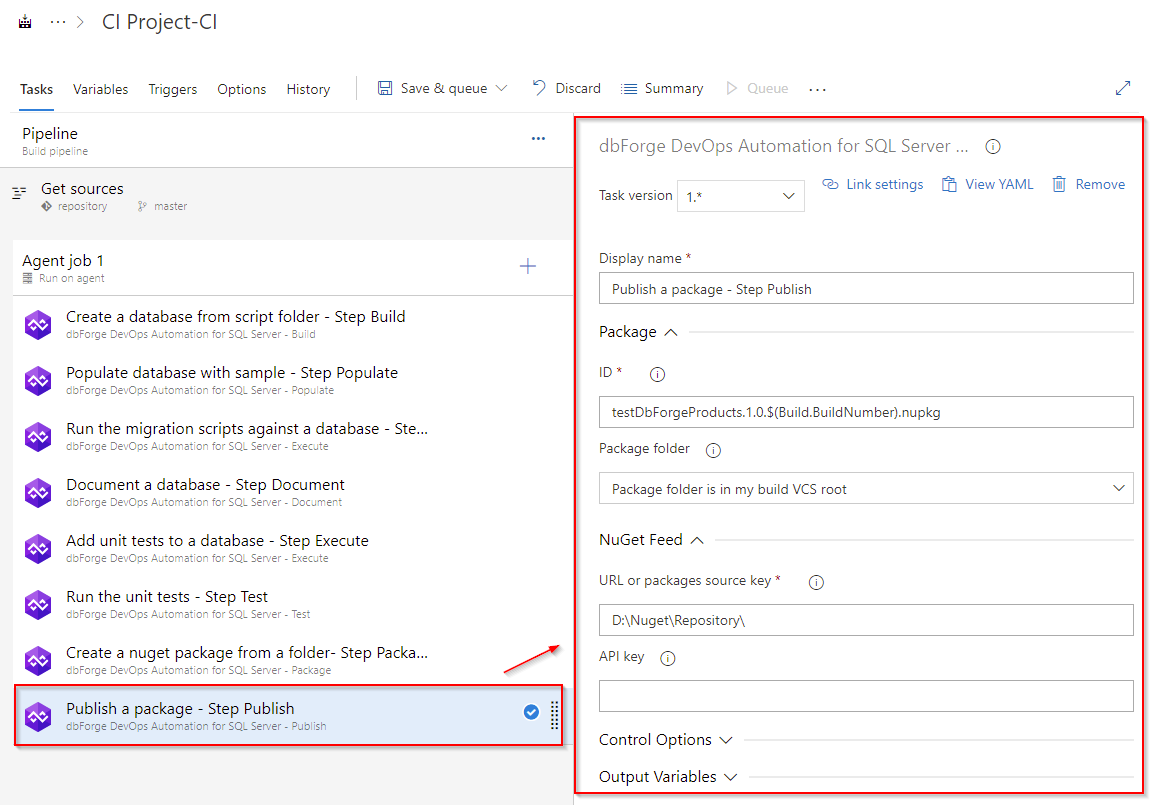
As you can see, we are going to publish the file to a local drive. If you want to publish the package on a package server, for example, "https:⁄⁄www.nuget.org", then you will need to set the API key parameter. The value for this parameter will be the token that is issued on this server.
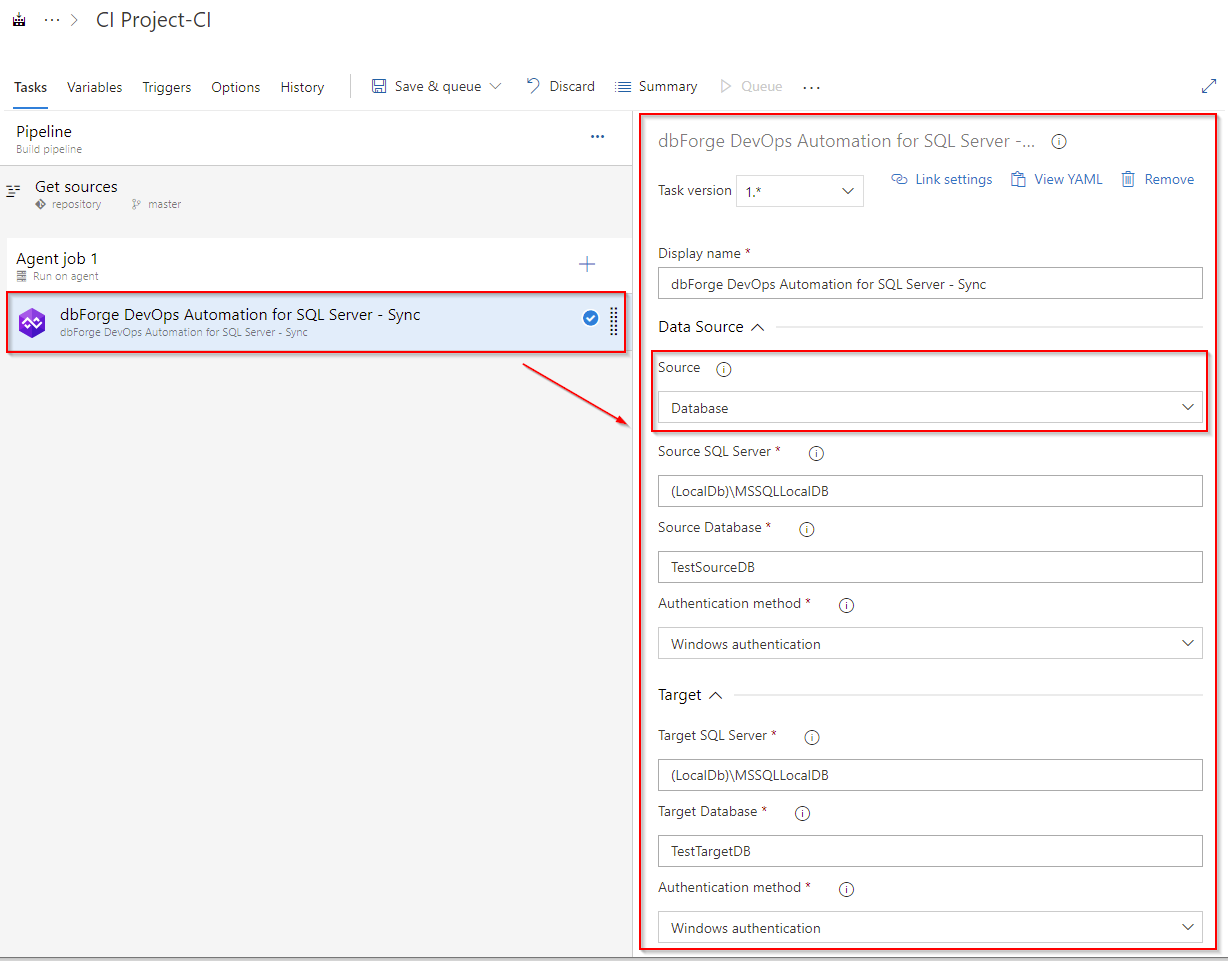
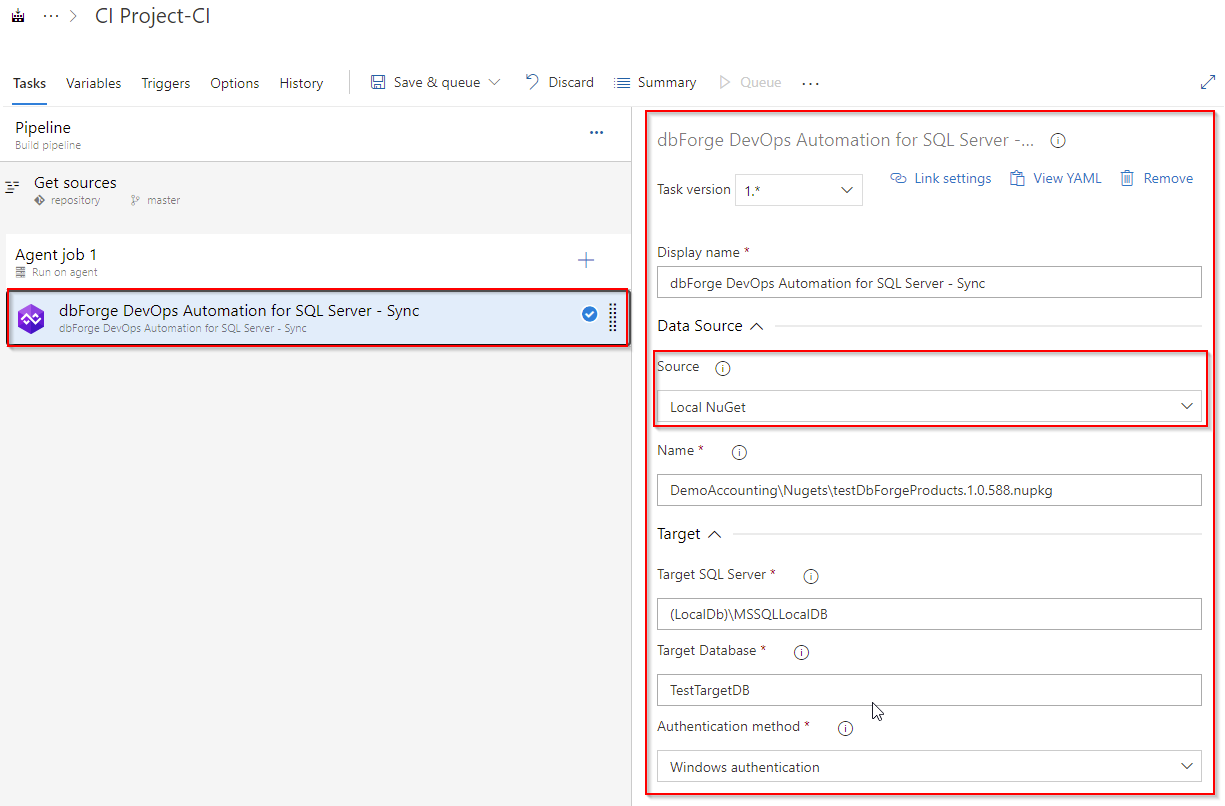
Creating the Sync task
Finally, you can create the Sync task. It should be noted that you can use the dbForge DevOps Automation for SQL Server – Sync task that you can additionally use for your more advanced process DevOps scenarios. You can select both a database and a NuGet package as a source.
Database as a source
NuGet package as a source
Details
It is necessary to clarify some points regarding the worked example given above.
In the Build and Package tasks, the ScriptsFolder folder was used. In this folder, the database creation scripts folder is stored. Also in the Execute task, we used the UnitTests folder. In this folder, the unit tests are stored in the form of SQL scripts.
At the very beginning, we created a connection to the GitHub repository and received these folders and their contents from it.
The structure of our repository is as follows:
\---AzureDevops
+---ScriptsFolder
| ...
+---UnitTests
...
Each time the pipeline starts a new run, the content is received from the remote repository to the working folder of the VSTS agent. The working folder of this agent is the root. The ScriptsFolder and UnitTests folders are merged into it.
The full path to the working folder of the VSTS agent would look something like this (the path may change depending on the parameters you set for the agent path and the name of its working folder at the stage of configuration):
C:.
+---vstsAgent
|
+--_work
|
+---a
+---b
+---s
+---ScriptsFolder
\---UnitTests
The folder structure for your CI process can differ. It depends on the database development model (state-based or migration scripts). It can contain a separate folder with a scripts folder or one or more folders with migration scripts. It can also contain a folder with one or more data generator project files as well as one or more folders with unit tests. You can build one or several pipelines to create databases, run specific unit tests, and populate the database with different test data.
Conclusion
We have observed a simple example of the CI process organization with the dbForge DevOps Automation Plugin for Azure DevOps that allows you to quickly configure the CI process to create a SQL Server database since its creation comes to using the predefined tasks from the extension in the sequence you need.
This plugin along with dbForge SQL Tools allow you to organize your own agile CI process of any complexity.
Watch our video tutorial to find out more about how to organize the DevOps process in Azure DevOps.
Additionally, watch these videos to discover how dbForge products can boost database development.
- How dbForge SQL Complete is involved in the Database DevOps process
- How to import data to SQL Server database with dbForge Data Pump during the DevOps process
- Creating database documentation during the Continuous Integration workflow
- How to automate database schema changes for the CI process during database deployment
- dbForge Source Control in the DevOps pipeline
- How dbForge SQL Complete is involved in the Database DevOps process
- Unit Testing for SQL Server Database in DevOps process