Setting Up Data Generator
This topic describes how to set up Data Generator to generate test data.
Tip
Before generating data, back up the database you want to populate.
If you’re not satisfied with the results, you can adjust the settings and regenerate the data.
To set up Data Generator:
1. Open the Data Generator Project Properties dialog in one of these ways:
- In the top menu, select Database > Tasks > New Data Generation.
- In Database Explorer, right-click the server connection or database and select Tasks > New Data Generation.
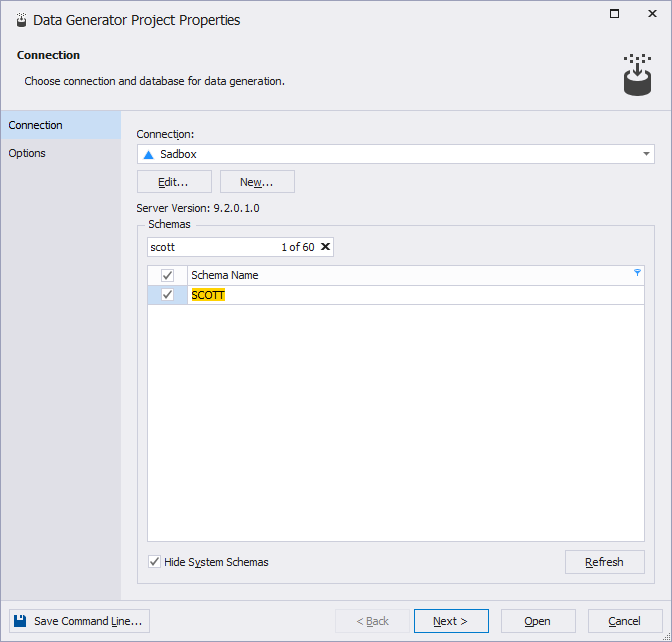
2. On the Connection page, select the connection and database for data generation.
Note
To create a new connection, click Manage in the Connection list. In the Connection Manager dialog, click New to add a new connection. For more information, see Managing connections.
3. On the Options page, set up data generation options.
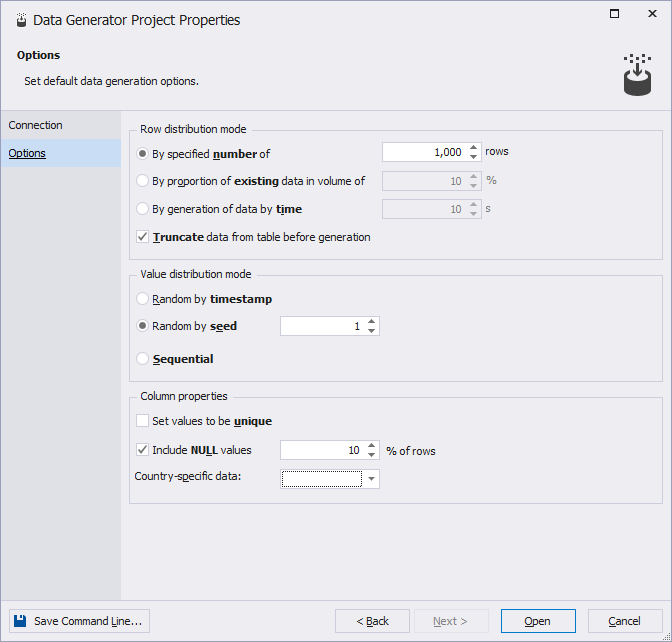
The table describes the data generation options.
| Name | Group | Description | Default value |
|---|---|---|---|
| By specified number of | Row distribution mode | Sets the number of rows to populate. | 1000 rows |
| By proportion of existing data in volume of | Row distribution mode | Specifies the percentage of rows to populate. | 10% |
| By generation of data by time | Row distribution mode | Specifies the time period in seconds during which data will be generated for each table. | 10 sec |
| Truncate data from table before generation | Row distribution mode | Determines if existing data in the target table should be removed before generating new test data.
|
|
| Random by timestamp | Value distribution mode | Populates every subsequent data generation with new random numbers. | |
| Random by seed | Value distribution mode | Generates values based on a specified seed. Repopulating the column will generate the same set of values each time. | 1 |
| Sequential | Value distribution mode | Generates new random numbers for each subsequent data generation. | |
| Set values to be unique | Column properties | Generates unique values. | |
| Include NULL values % of rows | Column properties | Specifies the percentage of NULL values to generate. |
10% |
| Include empty values % of rows | Column properties | Specifies the percentage of empty values to generate. | 10% |
| Country-specific data | Column properties | Applies data conventions of a specific country to the generated data. | United States |
4. Click Open to open a data generation project with the .dgen extension.
5. In the Tables and columns to populate pane, select the tables and columns for which you want to generate data.
Note
If dbForge Studio for Oracle encounters columns with unsupported data types, it can’t assign a generator to those columns. You’ll see this warning message:
Unsupported data type. You can assign a generator manually, or create a custom one by using Python Generator. Be aware that data insertion may fail if the generated values conflict with column rules or constraints.You can still include columns with unsupported data types in data generation; however, this might cause unpredictable behavior or unexpected results.
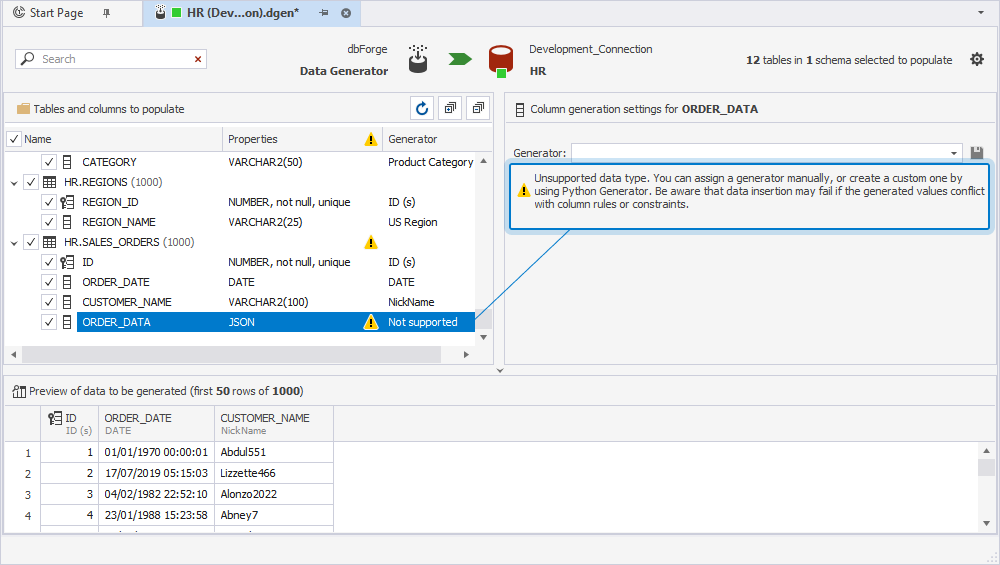
6. Select the table and set up table generation settings. Repeat this step for each table you want to populate with data.
7. Select the column and set up column generation settings. Repeat this step for each selected column.
Note
All changes are displayed in the preview pane in real time.
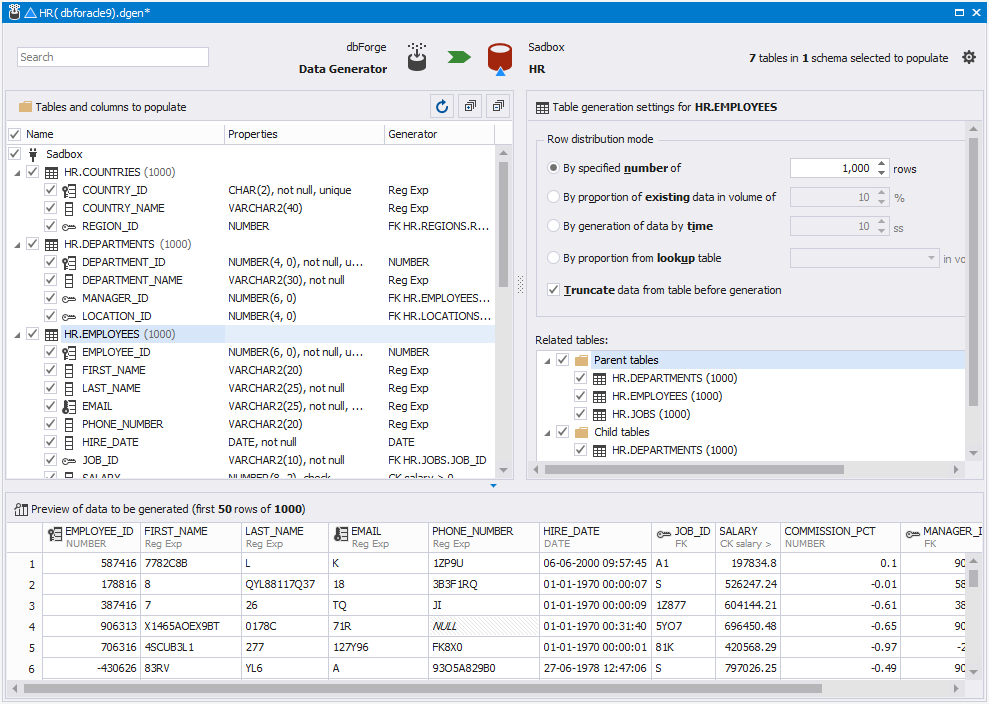
Warning
Data generation may fail if a column includes a foreign key that references a table not included in the generation process.
To resolve the issue:
1. Select the table causing the error.
2. In the Table generation settings pane, navigate to the Related tables section.
3. Include or exclude the related parent and child tables as needed.
8. Click ![]() to open the Data Population Wizard.
to open the Data Population Wizard.
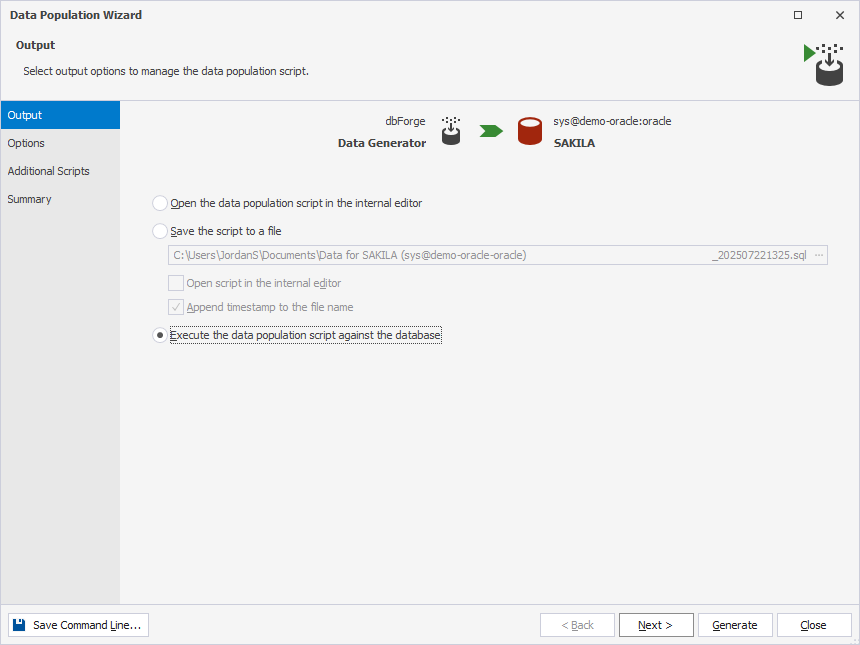
9. On the Output page, select the output option to manage a data population script.
- Open the data population script in the internal editor.
- Save the script to a file. In this case, specify the path to the file.
- Execute the data population script against the database without reviewing it.
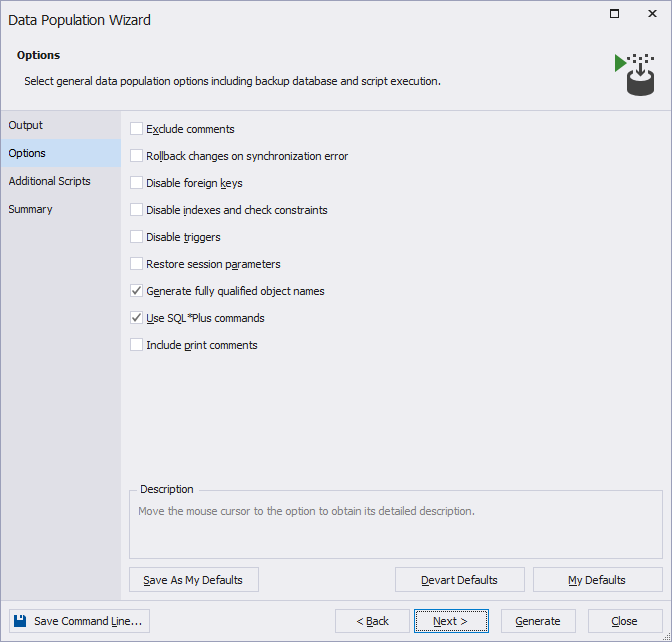
10. On the Options page, select general data population options.
Tip
You can click the name of an option to view its detailed description.
In the search box, you can start typing the option name. The options matching your search will be highlighted.
To save the options you’ve set for later use, click Save As My Defaults.
To use the default settings of the tool, click Devart Defaults.
To use the options you saved earlier, click My Defaults.
The table provides a list of data generation options available on the Options page.
| Name | Description | Default State |
|---|---|---|
| Exclude comments | Prevents comments generation in the data population script. | Off |
| Rollback changes on synchronization error | Automatically restores the database to the state preceding the synchronization if any error occurs. This includes rolling back a transaction and re-enabling disabled indexes and triggers. |
Off |
| Disable foreign keys | Drops foreign keys before data population. After the data population, the foreign keys are restored. |
On |
| Disable indexes | Turn non-unique indexes at the beginning of data population and re-enables them afterward. | Off |
| Disable check constraints | Drops the CHECK and NOT NULL constraints at the beginning of the data population process. After data population, the tool attempts to restore those constraints. |
Off |
| Disable DML triggers | Disables DML triggers before data population. After data population, the triggers are enabled. The option is applicable to tables and views. |
On |
| Restore session parameters | Restores session parameters, such as NLS_DATE_FORMAT, NLS_TIMESTAMP_TZ_FORMAT, NLS_TIMESTAMP_FORMAT, NLS_NUMERIC_CHARACTERS, NLS_NCHAR_CONV_EXCP, and TIME_ZONE after the script is generated. |
Off |
| Generate fully qualified object names | Generates fully qualified object names in the data population script. If the option is selected, the names of objects in the data population script will include a schema name. | On |
| Use SQL *Plus Commands | Uses the SQL *Plus commands, such as SET SQLBLANKLINES and SET DEFINE in the data population script. |
On |
| Include print comments | Adds comments to the output during the script execution. If print comments are included in the data population script, it is easier to locate the items in the output. |
Off |
11. On the Additional Scripts page, enter or choose the script you want to execute before or after data population.
You might use this option in scenarios, such as dropping existing data or temporarily disabling triggers before data generation, then re-enabling them afterward.
12. On the Summary page, review the data generation action plan and check for any errors or warnings that highlight potential problems.
13. Click Generate to complete the data generation process.