How to work with SQL Server graph databases
What is a graph database?
In simple terms, graph databases use graph structures for semantic queries with nodes, edges, and properties to represent and store data. Basically, these databases comprise a collection of nodes and edges (or relationships). A node represents an entity (for example, a person or a company) and an edge represents a relationship between the two nodes that it connects (for example, friends or likes).
Schema Compare supports the comparison and synchronization of NODE and EDGE tables by hiding the complexity that these objects have hidden columns and pseudo-columns. This facilitates working with these new object types.
Synchronize NODE and EDGE tables with Schema Compare
In a graph database, a node is generally created with the following SQL code:
CREATE TABLE Client (
Name NVARCHAR(MAX)
) AS NODE;
An edge, in its turn, is created with the following SQL code:
CREATE TABLE Connections AS EDGE;
Note
Edge tables do not need to contain any columns.
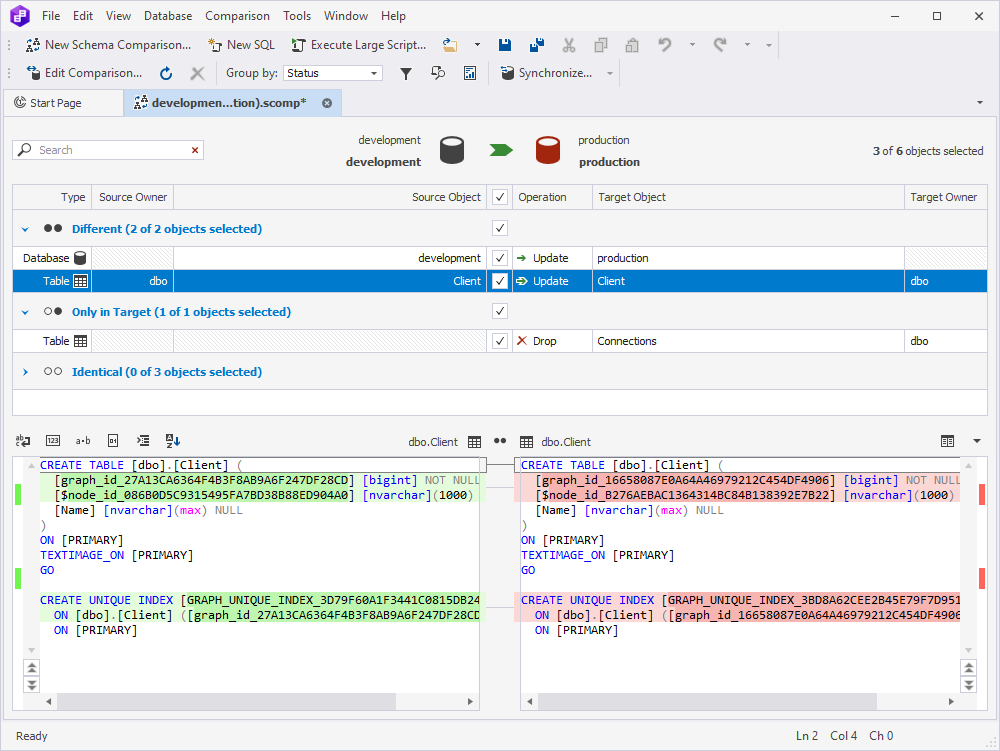
When synchronizing, NODE and EDGE tables appear in Schema Compare as regular tables. If a NODE or an EDGE table is selected for synchronization, the text comparer will display the code that will be used to create the table on the target database:
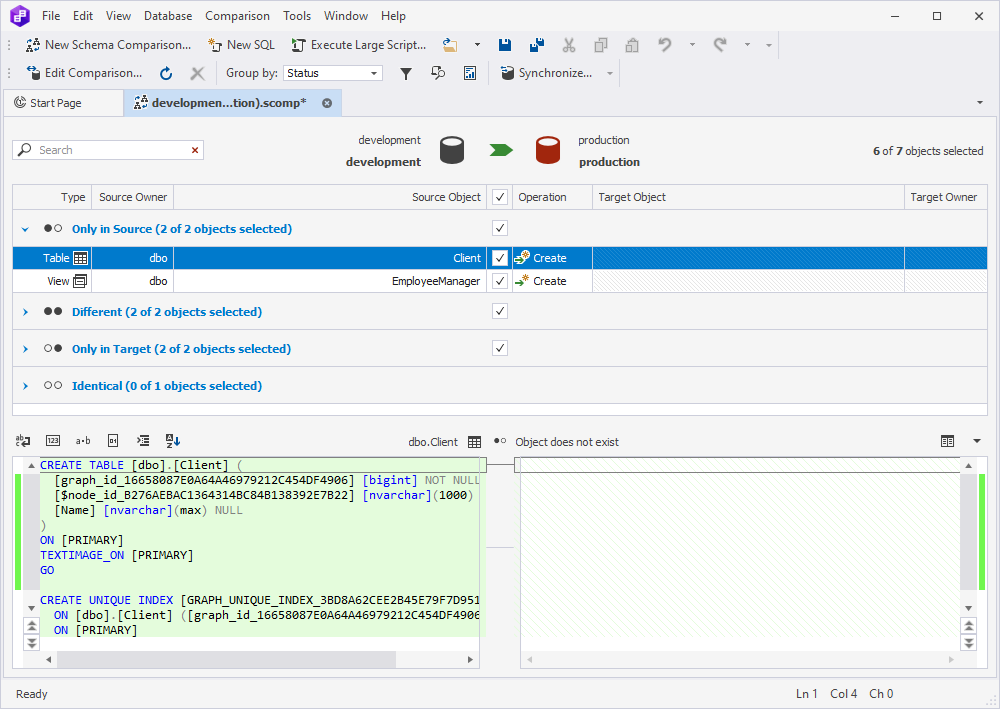
Note that, when synchronizing NODE and EDGE tables unique, non-clustered indexes are created automatically.
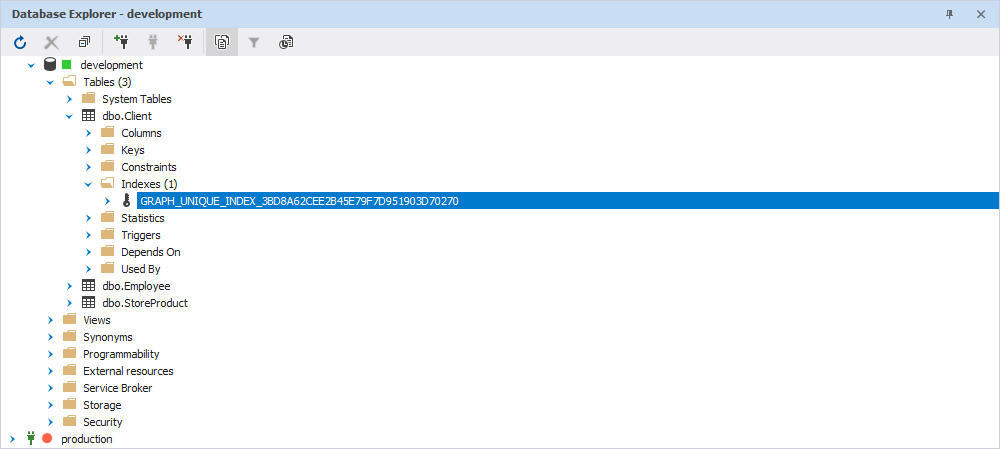
Synchronize indexes on pseudocolumns with Schema Compare
Creating an index on the $from_id and $to_id pseudo-columns in an EDGE table is a regular practice:
CREATE INDEX AnIndex ON connections ($from_id, $to_id);
The index is defined on the two pseudocolumns $from_id and $to_id but, internally, SQL Server defines such an index on the hidden columns of an EDGE table:
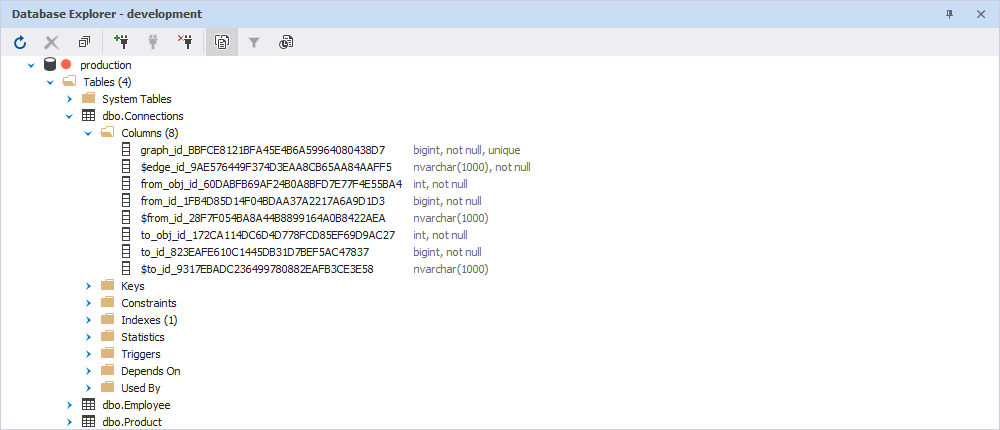
On synchronization, the Schema Compare tool creates the necessary indexes on the pseudocolumns, thus allowing NODE and EDGE tables and their indexes to be synchronized as easily as other tables in SQL Server.