What is a comparison key?
Comparison keys uniquely identify every single row in a table or a view for both the Source and Target.
When comparing data sources, dbForge Data Compare for PostgreSQL uses a matching primary key or other unique identifiers in each data source as the comparison key. This enables rows to be identified as matching and then compared.
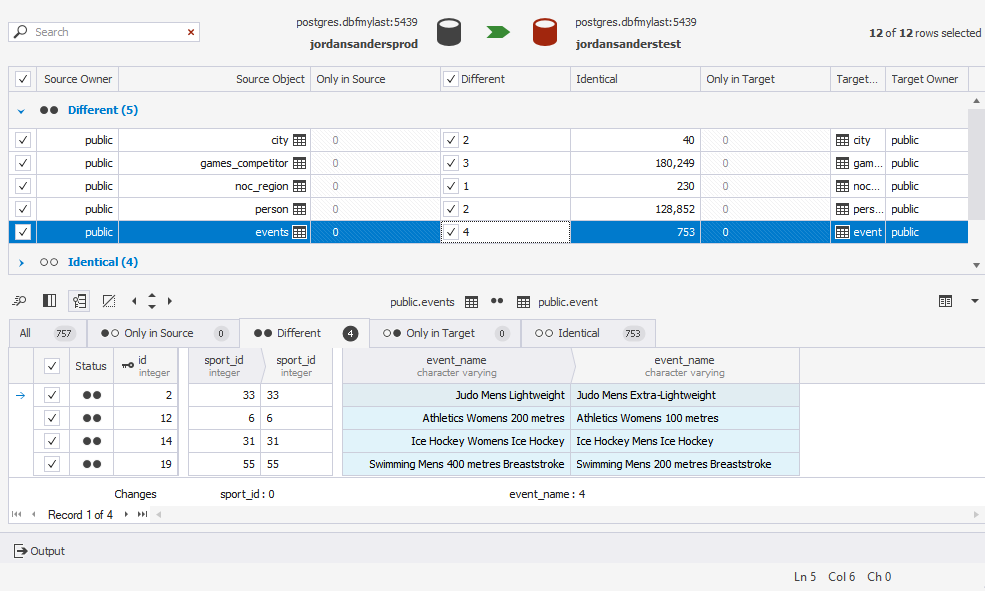
Consider the following example. Our production and testing databases each contain the events table.
As rows can be inserted and deleted, you can’t be sure that the fifth row in the production database is the same as the fifth row in the testing database. So if you simply compare rows in the order in which they appear in the table, it can result in a meaningless comparison. In a similar way, rows can’t be matched based on their sport_id values, as there might be more than one even within one sport group.
In the events table, id is a primary key. No two events can have the same id, and thus the rows are uniquely identified. Two matching id values in the production and testing databases, therefore, represent the same piece of real-world data.
Note
If there is no matching primary key or another unique identifier you need to set an appropriate comparison key when selecting tables, views, and columns for comparison. For example, if you know that two events never take place on the same day, you can select the event_date column as a comparison key.