Select tables, views, and columns for comparison
After you have created a project and selected your data sources, you can specify tables, views, and columns to be compared.
Note
dbForge Data Compare for PostgreSQL automatically maps tables and views with the same name and schema (owner). However, in case there are any differences between the data sources, for example, if two views have different names, they may not be mapped automatically, and you will have to map them manually.
You can map such objects manually using the Mapping tab of the New Data Comparison wizard.
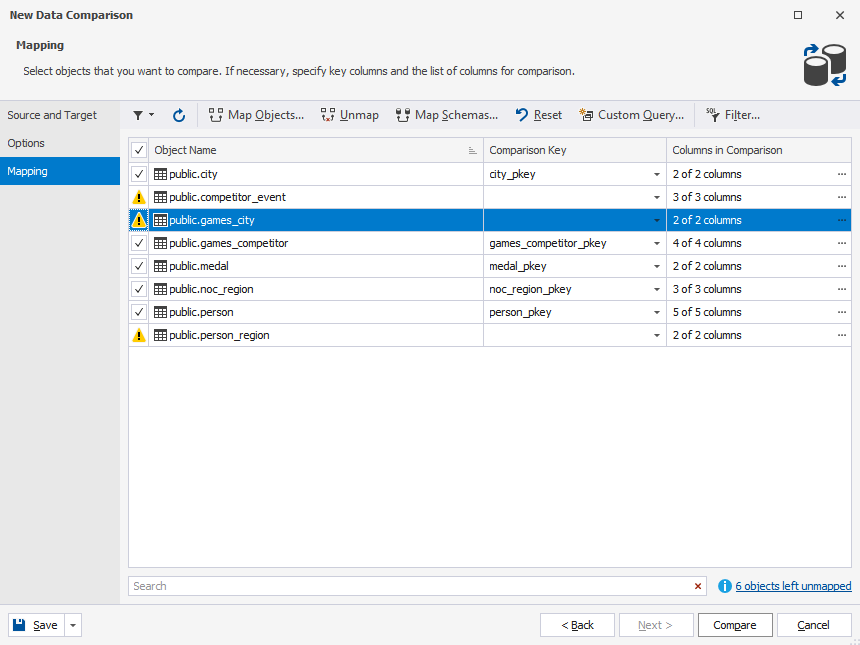
Auto-mapping options
The Mapping page allows you to:
- Select a comparison key for each table or view
- Select the columns to be compared
- Map objects
- Unmap objects
- Map schemas
- Reset mapping options to default
- Design a custom query
- Configure filter options
Select a comparison key for each table or view
To match rows in the two data sources, dbForge Data Compare for PostgreSQL requires a comparison key for each table or view.
The tool automatically selects a comparison key if:
- Tables contain a matching primary key, unique index, or unique constraint
- Views contain a matching unique clustered index
To learn more, refer to What is a comparison key?
If dbForge Data Compare for PostgreSQL is unable to identify a suitable comparison key for a table or view, a corresponding warning will be displayed.
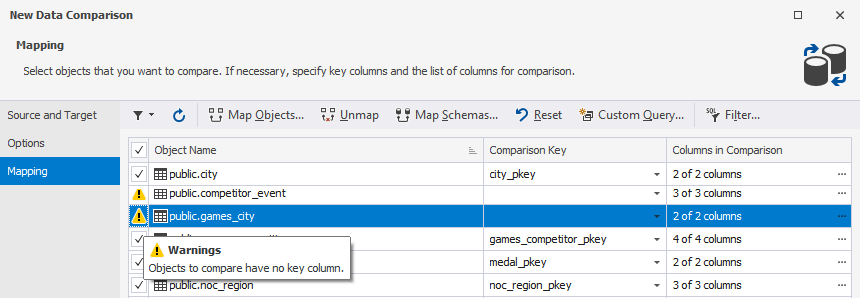
To set the comparison key for an object, click an arrowed button in the corresponding row of the Comparison Key column.

Select Custom and the Column Mapping window will open where you can select the columns that will comprise the key. Make sure that you’ve selected at least one column to be used as a comparison key. The difference between the columns will be ignored during comparison if the checkboxes in the Compare column are clear. The column will be excluded from the UPDATE, INSERT, and/or DELETE statements and will not be synchronized if the checkboxes in the Sync column are clear.
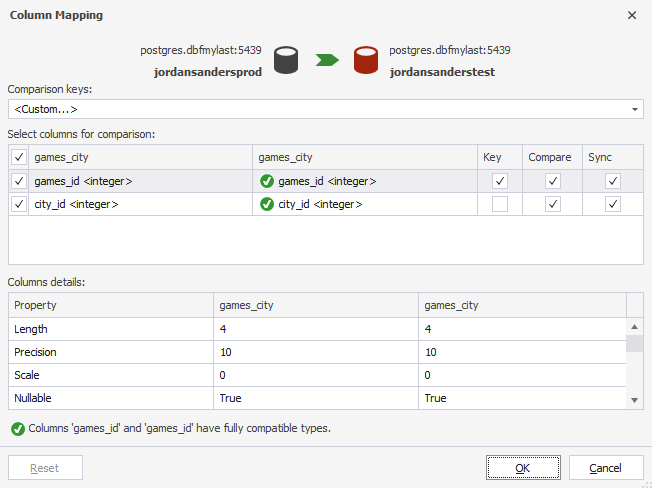
Note
- You cannot use as a comparison key those columns whose data type is xml, json, or array.
- In case Sync is selected, but Compare is not, the differences will not be displayed after the comparison. However, the synchronization will take place since the changes will be included into the synchronization script.
For more information about comparison keys, refer to What is a comparison key?
Select the columns to be compared
On the Mapping tab of the New Data Comparison wizard, the number of columns that will be compared for each table or view is displayed.
dbForge Data Compare for PostgreSQL allows customizing the comparison to consider only specific columns.
To select the columns to be compared, double-click the table or click … at the end of a row.
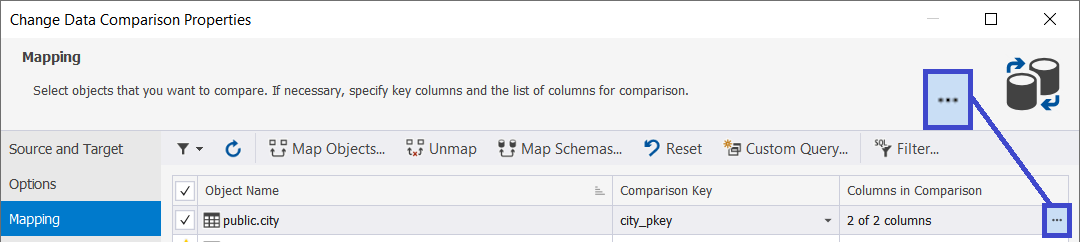
A dialog will be displayed with checkboxes to include or exclude the columns.
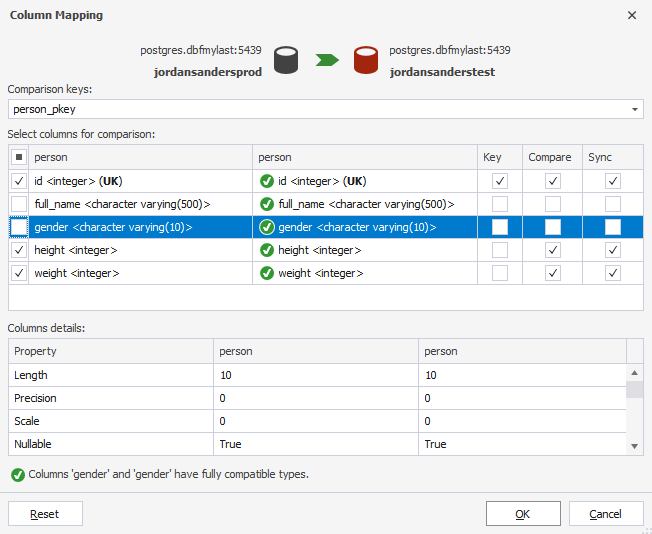
Note
You cannot exclude the columns that are used for the comparison key.
Map objects
By default, when you select the databases to be compared, configure comparison options and move to the Mapping tab of the New Data Comparison wizard, dbForge Data Compare for PostgreSQL automatically maps all the objects having the same names and data types in the selected databases.
To map objects left unmapped, on the Mapping tab, click Map Objects.
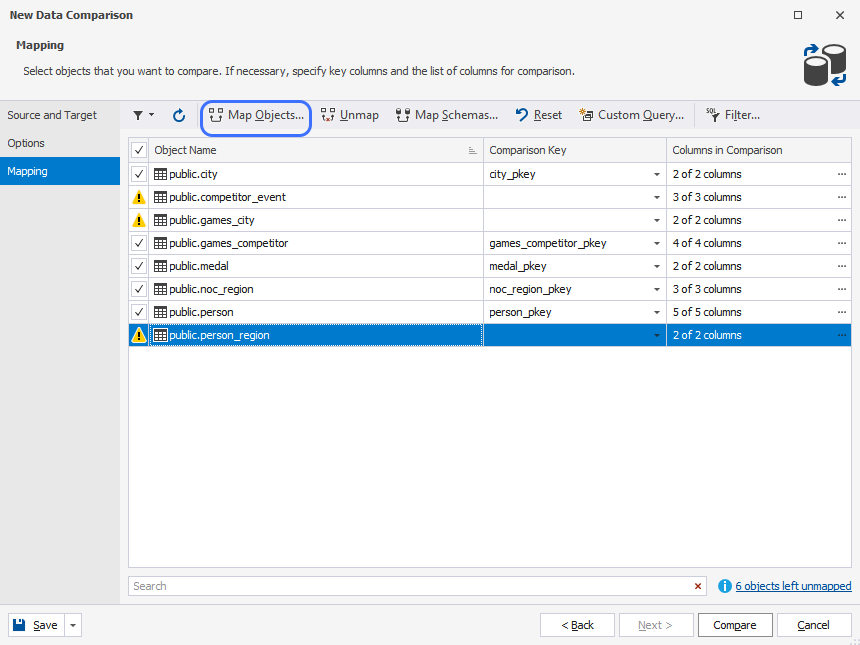
In the Objects Mapping dialog that opens, you can select a table or view you want to map.
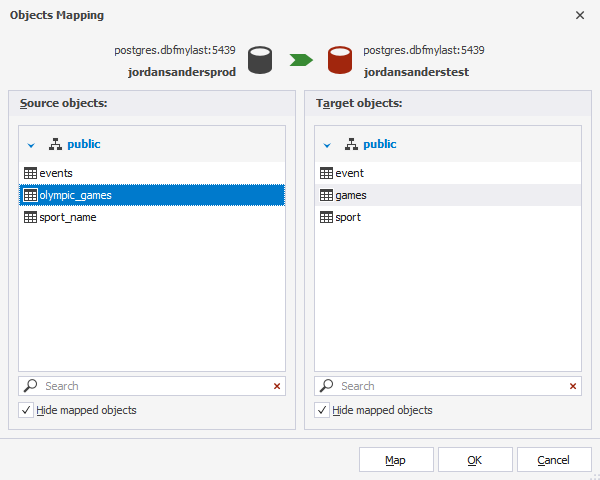
Having selected the required objects, click Map. The selected objects will appear in a list of mapped objects on the Mapping page of the New Data Comparison wizard.
Note
When tables or views that you are mapping contain columns with incompatible data types, dbForge Data Compare for PostgreSQL won’t be able to compare those columns, and they will be excluded from the comparison. Having mapped the objects, you may encounter mapping warnings, displayed as Caution icons. We recommend to study warnings thoroughly before moving on with the comparison and synchronization.
Unmap objects
You can unmap objects in several ways:
- Click Unmap in the upper menu bar. In this case, all the mapped objects will be unmapped.
- Select a required object from a list and click Unmap in the upper menu bar. In this case, only selected objects will be unmapped.
- Select a required object from a list, right-click it, and then select the Unmap option from the menu that appears.
Note
Other mapping options available in the menu that appears after right-clicking the object from a list:
- Exclude all but this
- Unmap all but this
- Unmap all invalid
Map schemas
When you start a new data comparison project and you select your data sources, dbForge Data Compare for PostgreSQL automatically maps objects with the same schema.
However, the tool allows comparing objects having the same name, but belonging to different schemas. It can be useful if schemas were renamed, and you want to synchronize data between a database with new schema names and a database with old schema names.
To achieve that, you need to map the schemas as required.
To map schemas:
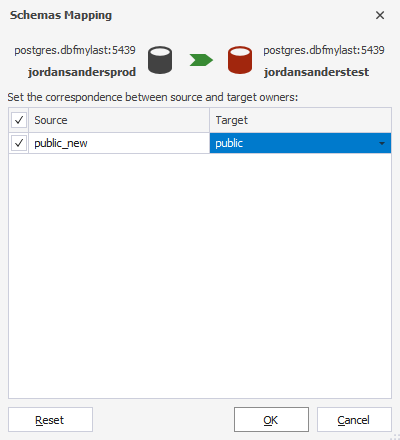
1. Switch to the Mapping tab of the New Data Comparison wizard.
2. Click Map Schemas on the toolbar.
3. In the Map Schemas dialog that will appear, map the source schema with the target schema as required. To do this, click the drop-down arrow button in the corresponding Target column cell and select the required schema from the drop-down list.
4. After you’ve mapped all schemas you need, click OK. If you want to restore the original mapping, click Reset.
Note
dbForge Data Compare for PostgreSQL supports only one-to-one schema mapping. If you need to synchronize data between one source schema and several target schemas or vice versa, you need to perform several comparison and synchronization operations.
Reset mapping options to default
dbForge Data Compare for PostgreSQL allows you to quickly and easily reset mapping options to default.
To do this, click Reset in the toolbar. The default mappings will be restored.

Design a custom query
You can use the Custom Query functionality to compare custom results received after query execution instead of comparing whole tables or views.
To do this:
1. On the Mapping page of the wizard, click Custom Query.
2. In the Custom Queries Mapping dialog that opens, select the Query or Table or View radio buttons both for the Source and the Target.
3.
- If you select the Table or View option, you will be able to map tables or views from the list.
- If you select the Query option for the Source, the Target or both, write query name in the field near Name (if the name assigned by default is not appropriate).
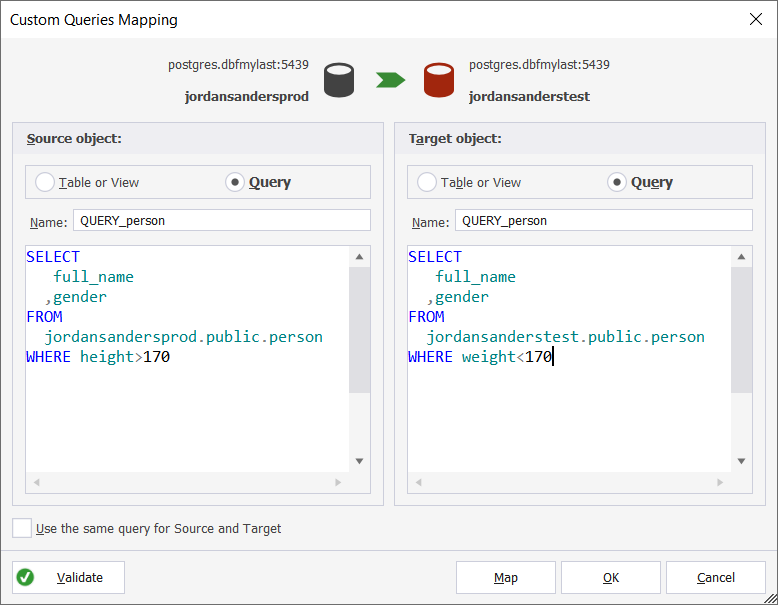
4. Type the needed query in the SQL field.
5. Click Validate to validate your query, if necessary.
6. Click Map.
7. Click OK to close the dialog.
Tip
Click Cancel to close the dialog and discard mappings.
Click Reset to restore the default mapping of objects.
Configure filter options
By default, dbForge Data Compare for PostgreSQL compares all rows in the selected tables or views. In case they contain a large amount of data, the comparison can take a lot of time and even result in running out of disk space. You can simply avoid those by filtering the rows to be compared by applying a WHERE clause to the comparison.
To filter the comparison with a WHERE clause:
1. On the Mapping page of the New Data Comparison wizard, select the object to apply the filter to.
2. Click Filter from the toolbar.
3. In the WHERE Filter dialog, that opens, type a valid Transact-SQL WHERE clause.
You can easily get a list of columns by calling the context menu. For this, right-click in a field for query, hover over Insert Column and click to insert a required column.
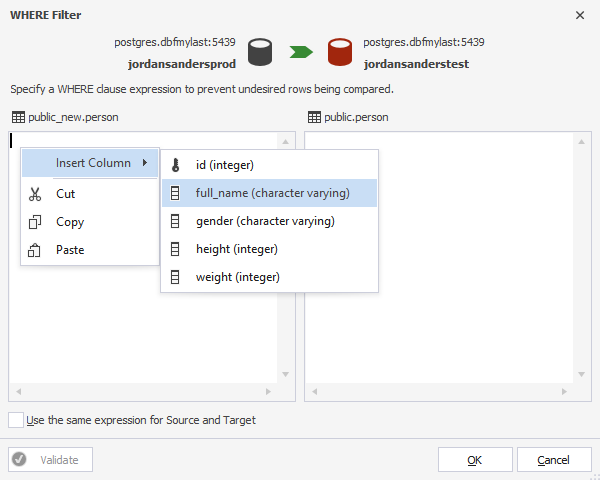
Thus, you don’t need to recollect columns names.
4. If you want to apply the expression to both the Source and the Target, select the Use the same expression for Source and Target checkbox.
5. Click OK to apply the filtering options.
6. The filtered object will be marked with a filter icon in the grid on the Mapping tab.
![]()
Mapping warnings
After objects are mapped for comparison and synchronization, you may encounter warnings on the Mapping page of the New Data Comparison wizard. They are displayed with the Caution icon instead of a checkbox in the grid.
To read the warning messages, point to the warning icon. All warnings for this object will appear as a hint.
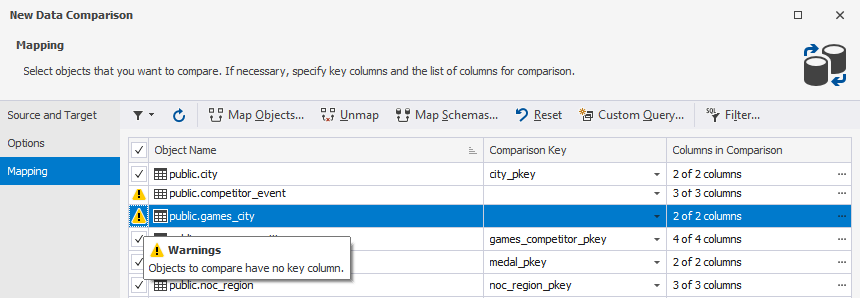
We recommend looking through the warnings before moving to the comparison.
The list of possible warnings:
| Warning | Description |
|---|---|
| Cannot convert parameter value to X data type. | This warning appears when a query with parameter is run in a SQL document and the form asks for a value of the specific type for this parameter, but a value of a different type was entered. This warning is critical. To solve it, you should enter correct parameter value. |
| Conversion is possible, but may fail in case of incompatible data. | Conversion between columns X and Y is possible, but may fail in case of incompatible data. This warning appears if columns of very similar, but yet different types are mapped, for example, CHARACTER(255) and CHARACTER VARYING(255). This warning is not critical for comparison, but it’s of medium importance for synchronization. To solve this problem, you should use custom query with explicit conversion to the target type in the source. |
| Columns have different collations. | Columns X and Y have different collations. This warning appears if mapped columns have different collation. This warning may result in incorrect comparison of values. To solve it, you should use custom query in the source that sets the collation to the one that is used in target explicitly. |
| Columns are enum types. | Columns X and Y are enum types and may not be converted. This warning appears when Enum is used as column data type. The application does not support Enum data type. It is critical. To solve it, you should use custom query in source and target that will convert such types to the supported data types explicitly. In this case comparison will be possible, but synchronization will not. |
| Columns have different precisions. | Columns X and Y have different precisions, migrating the data may cause overflows. This warning appears if columns have different precision. It is not critical for comparison, but has medium importance for synchronization. To solve it, you should use custom query in source that will perform explicit conversion to the target data type. |
| Date or time columns have different data format. | Date or time columns X and Y have different data format, migrating the data may cause truncation. This warning appears if date and time in mapped columns are stored in different format. The importance of this warning is medium. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Decimal columns have different precisions or scales. | Decimal columns X and Y have different precisions or scales, migrating the data may cause rounding or overflows. This warning appears if decimal columns have different precision or scale. It is not critical for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Decimal and Integer columns have different precisions and scales. | Decimal and Integer columns X and Y have different precisions and scales, migrating the data may cause rounding or overflows. This warning appears if decimal and integer columns have different precision and scale. It is not critical for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Float and Integer columns have different precisions and scales. | Float and Integer columns X and Y have different precisions and scales, migrating the data may cause rounding or overflows. This warning appears if float and integer columns have different precision and scale. It is not critical for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Numeric columns have different precisions. | Numeric columns X and Y have different precisions, migrating the data may cause rounding. This warning appears if numeric columns have different precision. It is not critical for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Columns have different sizes. | Columns X and Y have different sizes, migrating the data may cause truncation. This warning appears if columns have different size, for example, CHARACTER(255) and CHARACTER(300). It is not critical for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will convert the type to the one used in target. |
| Columns X and Y have incompatible types. | This warning appears if data types in mapped columns cannot be converted. It is critical. To solve it, use custom query with explicit conversion to the needed data type, if such conversion is possible. |
| Source column allows Nulls which can not be stored in target. | Source column X allows Nulls which can not be stored in target column X, migrating the data may cause an error. This warning appears if source column allows Nulls which cannot be stored in target. It is not critical at all for comparison and is of medium importance for synchronization. To solve it, you should use custom query in source that will exclude rows with Null or will replace them with another value. |
| There are unsupported types in the columns. | This warning appears if there are unsupported types in columns. It is critical. To solve it, you should use custom query with explicit conversion to the supported data type if such conversion is possible. |
| Maybe you are trying to connect to PostgreSQL server version 7. This server version is not supported. Connection error: X | This warning appears if an error occurred on connection attempt, for example, if server version is not supported. It is critical. To solve it, you should check server version and make sure it is configured correctly, also check if the parameters specified in dbForge connection dialog box are correct. |
| Bit value can contain only X and Y digits. | This warning appears if on reading data in bit types a value different from X and Y is found. Such error can occur if explicit conversation to bit type is available in source of target. It is critical - comparison of such table is impossible. To solve it, you should correct conversion. |
| Support is done for PostgreSQL versions starting 8.3. | The X version of the PostgreSQL server (Host: Port: ) is not supported. This warning appears if unsupported server version is found on connection. It is critical. To solve the problem, you should contact Devart support and inform about the PostgreSQL server version that is not supported. |