Setting a comparison key
You can specify a comparison key for a table and configure how dbForge Studio for MySQL selects a comparison key automatically.
What is a comparison key?
A comparison key is a column or a set of columns that uniquely identifies each row in a table or view in the source and target databases. During data comparison, dbForge Studio uses the comparison key to match rows between the databases. If no suitable key exists, you can specify a custom comparison key or select the required constraints for comparison.
Example
Consider the following scenario.
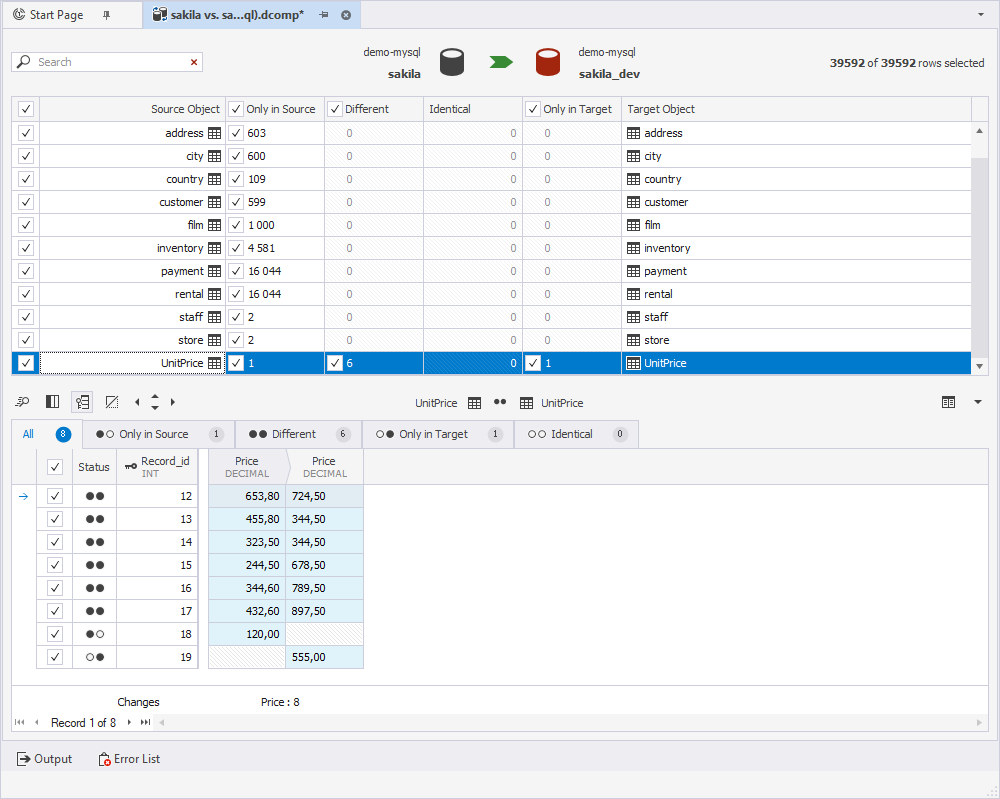
Both the sakila and sakila_dev databases contain the UnitPrice table.
Since rows can be inserted or deleted independently in each database, the position of a row may differ between environments. For example, the fifth row in the UnitPrice table in the sakila database may not match the fifth row in the same table in the sakila_dev database. Therefore, comparing rows by their order is unreliable.
The Price column also cannot be used to match rows, since multiple records may have the same price. Instead, rows should be matched using the Record_id column.
In the UnitPrice table, Record_id is the primary key, which means each value uniquely identifies one row. When you compare rows with the same Record_id values in both databases, you can match the corresponding rows, provided that Record_id represents the same real-world record in both environments.
Specify a comparison key
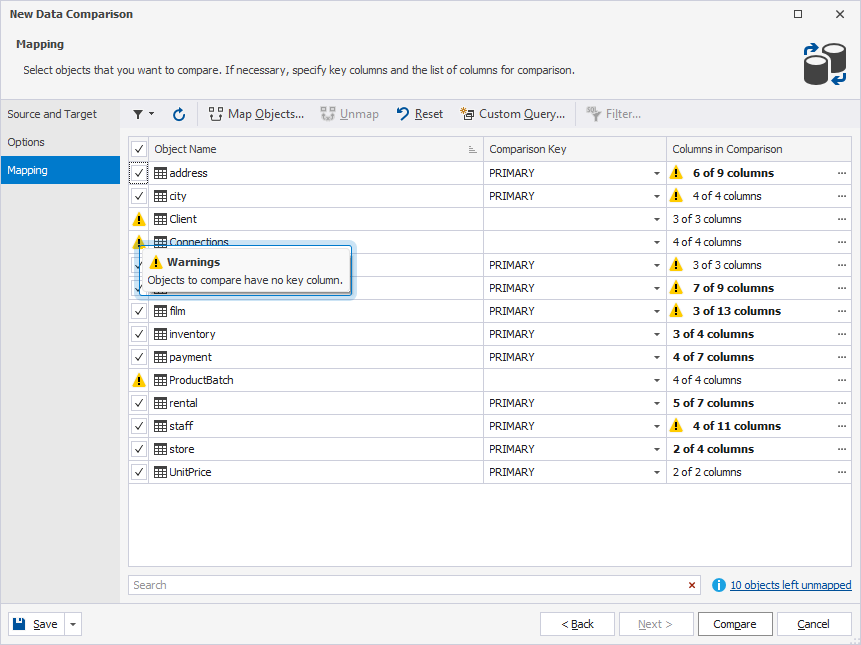
If dbForge Studio can’t find an appropriate comparison key for a table or view, the following warning appears on the Mapping page of the New Data Comparison wizard: Objects to compare have no key column. This means that you must specify a comparison key for correct data comparison.
To specify a comparison key:
1. On the Mapping page, in the Comparison Key column, click the arrow for the table that doesn’t have the comparison key, then select Custom.
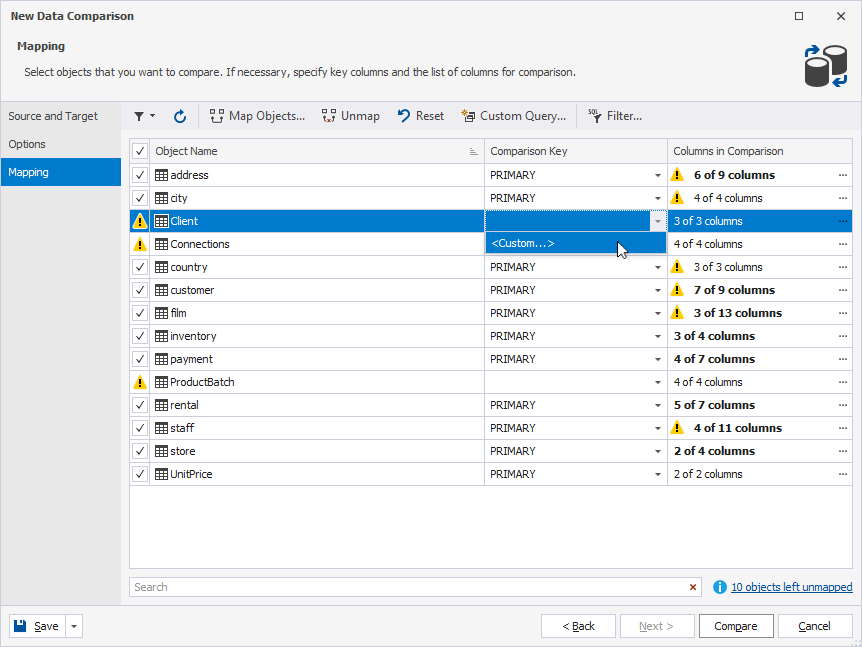
2. In the Column Mapping dialog, in the Key column, select the checkboxes for the columns you want to set as comparison keys.
Note
You must select at least one column as a comparison key.
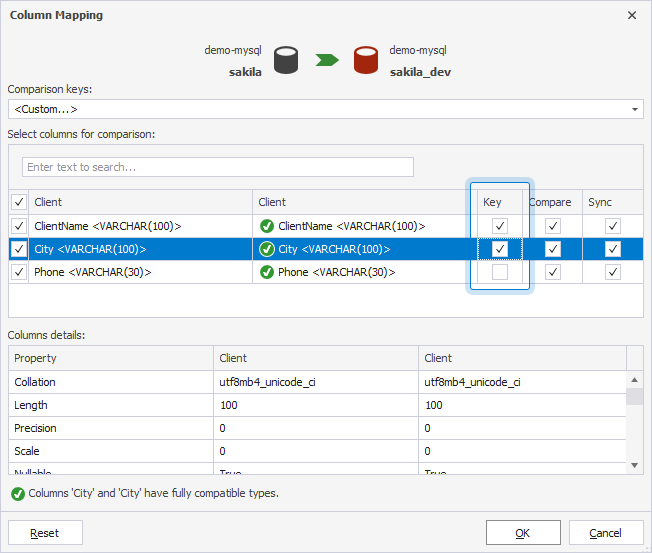
3. Click OK.
The Client table is now mapped.
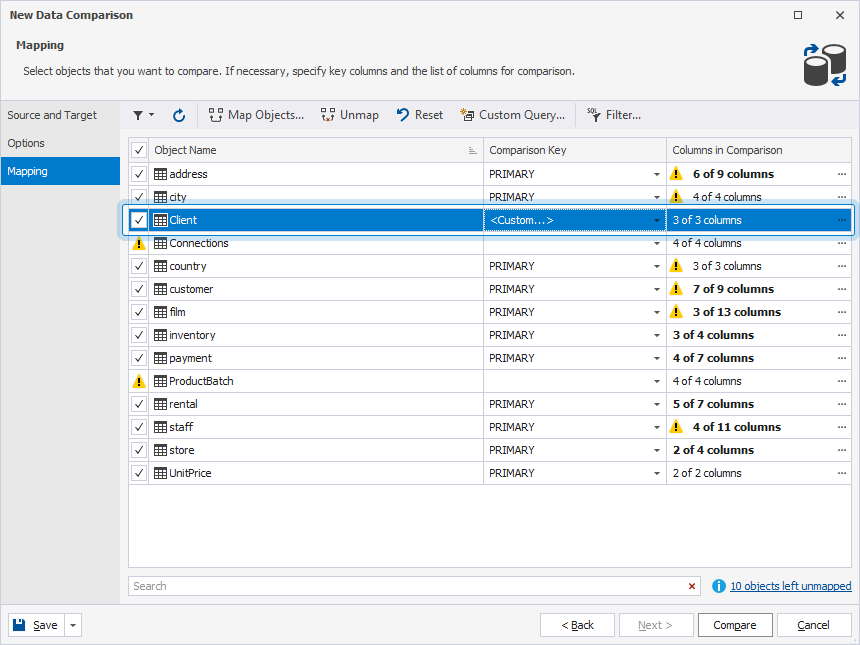
4. Click Compare.
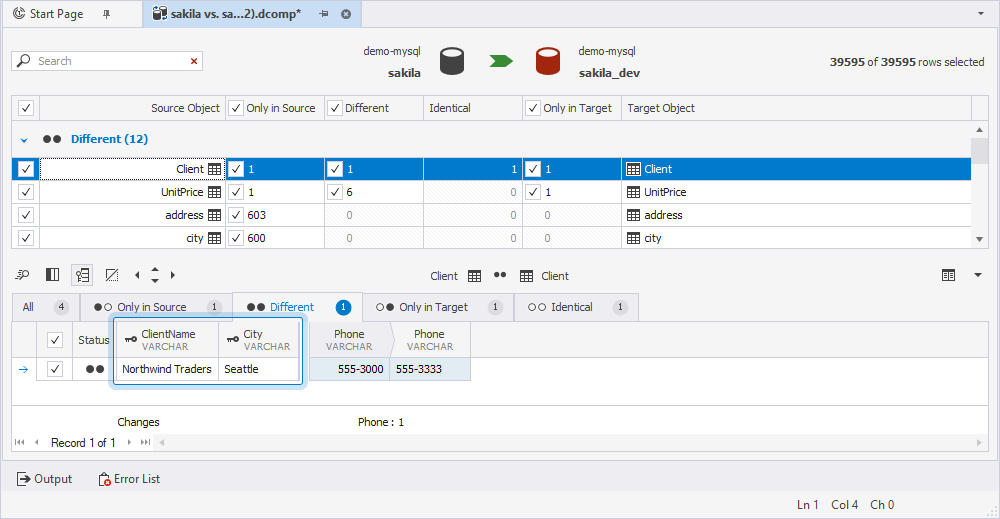
dbForge Studio successfully compared the data. The data comparison document displays the results, even though the table has no primary key, and all different rows are clearly identified.
Recommendations for working with comparison keys
When you work with comparison keys, consider the following:
- Use stable, unique columns as comparison keys and avoid
NULLvalues whenever possible. Columns used as comparison keys must be defined asNOT NULLin both the source and target databases to avoid warnings and missing rows. - Minimize the use of composite keys whenever possible. Composite keys, which consist of multiple columns, can increase comparison overhead. If a single column is unique, use that column as the key.
-
Before synchronization, verify that the selected key is unique. To do this, run the following query:
SELECT KeyCol, COUNT(*) FROM <table_name> GROUP BY KeyCol HAVING COUNT(*) > 1;If this query returns any rows, the selected column is not unique and may cause ambiguous matches during comparison.
-
For tables without a primary key or unique constraint, select the most distinctive columns. For example, if neither table contains a unique identifier, a combination of several columns may be used as a comparison key, provided that the combination uniquely identifies each record.
- Review the warnings on the Mapping page and fix any issues before you run the comparison.
Limitations
- You can’t use columns with the following data types as comparison keys:
BLOB,TEXT,MEDIUMTEXT,LONGTEXT,MEDIUMBLOB,LONGBLOB, andJSON. - Tables without a primary key or unique identifier may require manual key selection.
- Using multiple large string columns as a composite comparison key can increase memory usage and slow down comparison operations.
- If the checkboxes in the Sync column are selected but the checkboxes in the Compare column are not, differences aren’t displayed after the comparison. However, synchronization still occurs, as the changes are included in the deployment script.
Configure the comparison key selection strategy
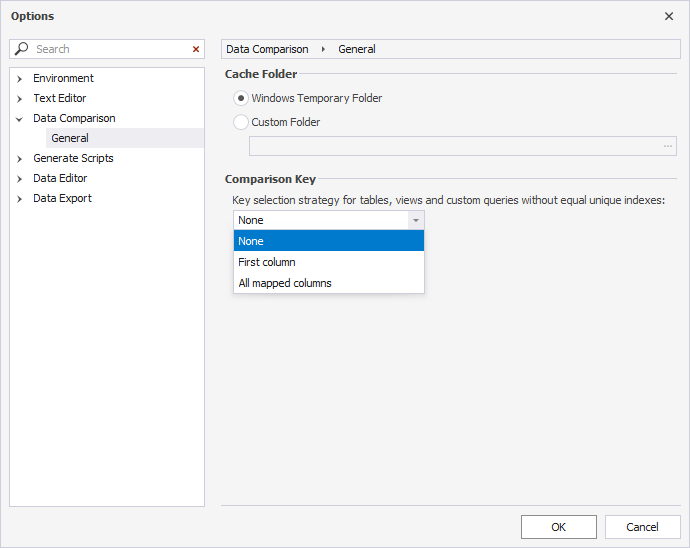
1. On the menu bar, select Tools > Options.
2. Navigate to Data Comparison > General.
3. Under Comparison Key, select one of the comparison key options:
- None (default) – Excludes rows from the comparison when no comparison key is assigned.
- First column – Uses the first mapped column as the comparison key.
- All mapped columns – Uses all mapped columns in the table or view as the comparison key.
Warning
These options enable automatic key assignment when no comparison key exists, but they should be used carefully.
- When you select First column as the comparison key for a column that is not unique, dbForge Data Compare marks these rows as conflicts, excluding them from synchronization.
- When you select All mapped columns, each row must be uniquely identified by the combined values of the mapped columns. Otherwise, duplicate rows may cause conflicts during comparison and synchronization.
4. Click OK.