How to create a pivot table
This topic describes how to create pivot tables and efficiently analyze data using pivot tables.
Pivot table
Pivot table is a table that allows you to easily rearrange or pivot your data by a simple drag of a mouse until you get the layout best for understanding the data relations and dependencies. You can create pivot tables using the pivot table view of the SQL document.
Before creating a pivot table, note that:
- You should connect a pivot table to the data you want to display and rearrange in the pivot table. The data source can be a query in the SQL or query document.
- Not all the data source tables are good for converting into a pivot table. The data source should contain a column with duplicated values, which can be grouped, and a column with numeric data, which can be used to calculate grand totals and custom totals.
- You should place data source fields from the Data Source view into the pivot table areas to add the data to the pivot table.
To create a pivot table:
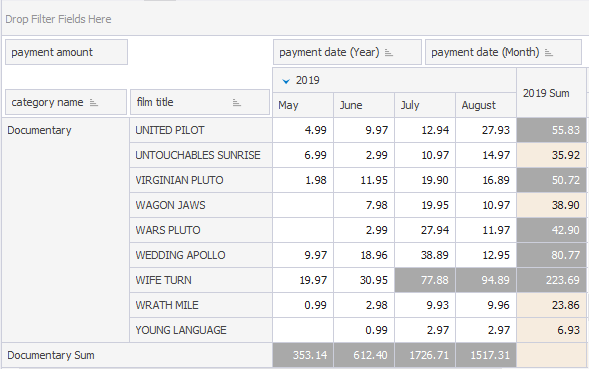
1. Open a query document by clicking New Query on the Standard toolbar to select it as a data source for a pivot table. In Database Explorer, select required tables from a database and drag them to the query document. They are displayed as shapes with columns. In table shapes, select check boxes next to the required columns. We would like to analyze which film category had more rentals and brought the highest revenue in each particular month. Therefore, we select the following four columns: category name, film title, payment amount, and payment date.
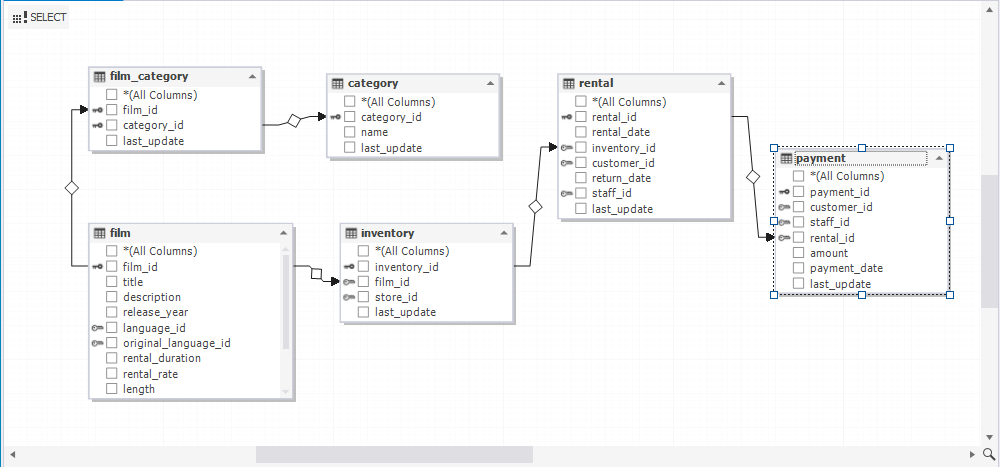
2. Switch to the Pivot Table view to see the pivot table template. The Data Source view opens automatically with the fields (when dealing with pivot tables, data source columns are referred to as fields) specified in the query document.
Note
Any field with date or time data format is decomposed in the Data Source view to its components.
In this case the payment date field has been decomposed to four fields: year, month, day, and master field. The latter allows you to add the three payment date sub-fields to a pivot table at once.
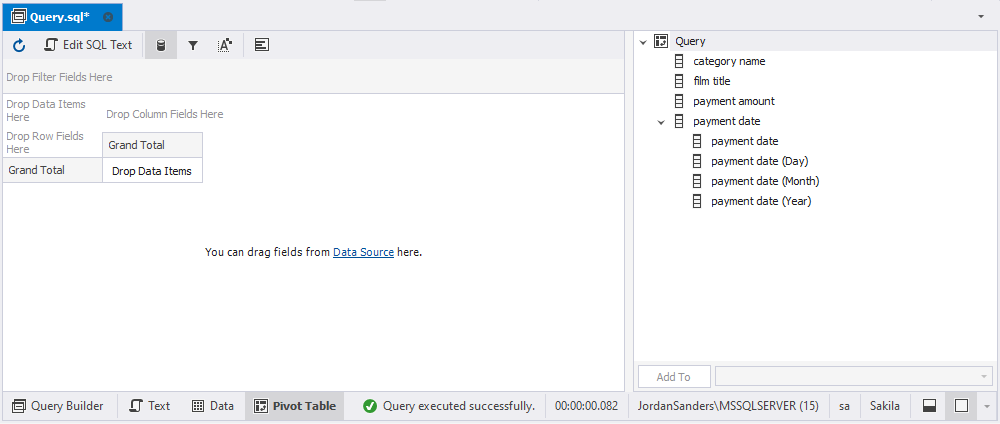
3. Customize the location of the selected fields in the pivot table:
-
Category name and film title field contain string values, some of them are rather long. It will be good to place these field as row field to see their values vertically at the left of the pivot table. In this case you will have the long but tighter table.
-
Payment amount field has numeric data, so it is reasonable to place it into data area where grand totals and custom totals can be calculated.
-
If the Payment date field is displayed as column field, i.e., horizontally in the pivot table, you will be able to group payment amount figures by payment day, month, and year. Let’s add only Month and Year of payment date to simplify the analysis. Note, you can change the layout and display category name and film title CategoryName field as Column field and payment date as Row field. No limitations, the data can be easily rearranged until it becomes the most readable.
To add fields to the pivot table, drag them from the Data Source view to a required pivot table area or highlight a field in the Data Source view, select a required area from the Destination area drop-down list and click Add To or just press ENTER.
To add two or more fields to the same pivot table area, add the first field and then drop the second one before or after the first field in the area.
4. Now the pivot table contains the following:
- Category name and film title as row fields
- Payment date (Year) and (Month) as column fields
- Payment amount as data field
- Custom totals and grand totals that are automatically calculated for the added fields
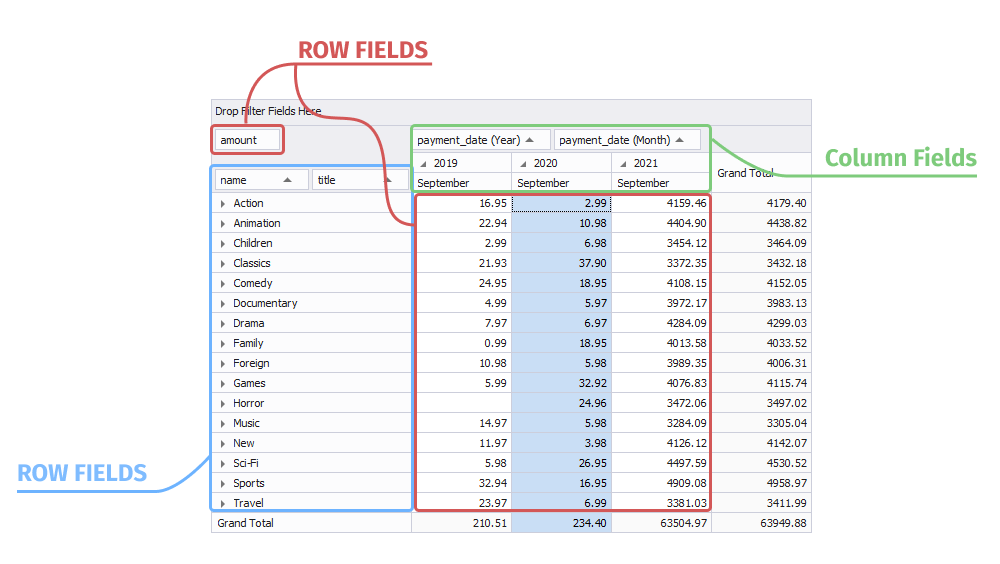
The film titles may be hidden by collapsing the category name nodes to define the most profitable category by month or year. The names of employees may be hidden by collapsing the department name. To sort the values in the fields, click Sort. You can filter payment amounts, for example, to display only payment amounts in 57. Click the button in the payment date (Year) field and clear 2006 in the dialog box.
5. If required, you can apply conditional styles to the pivot table to better process the data. For example, you may need to quickly see what films brought monthly revenue higher than $40.
- Click Conditional Styles on the Pivot Table toolbar or right-click the pivot table header and select Conditional Styles from the menu. In the dialog that opens, click Add to add a new condition.
- Select payment amount in the list of fields, Greater or Equal in the Condition field, enter 0 in the Value1 field. In the Apply To section clear all the check boxes except the Cell check box. In the Appearance section, click the BackColor field and select the LightCyan color to highlight the cells.
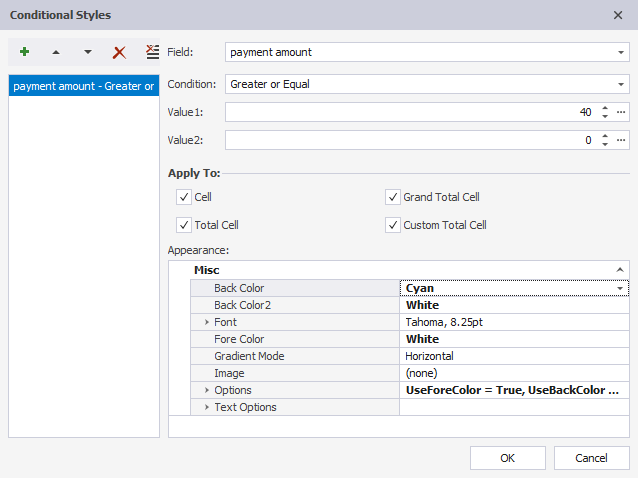
See the result in the pivot table.
Download dbForge Studio for SQL Server and try it absolutely free for 30 days!