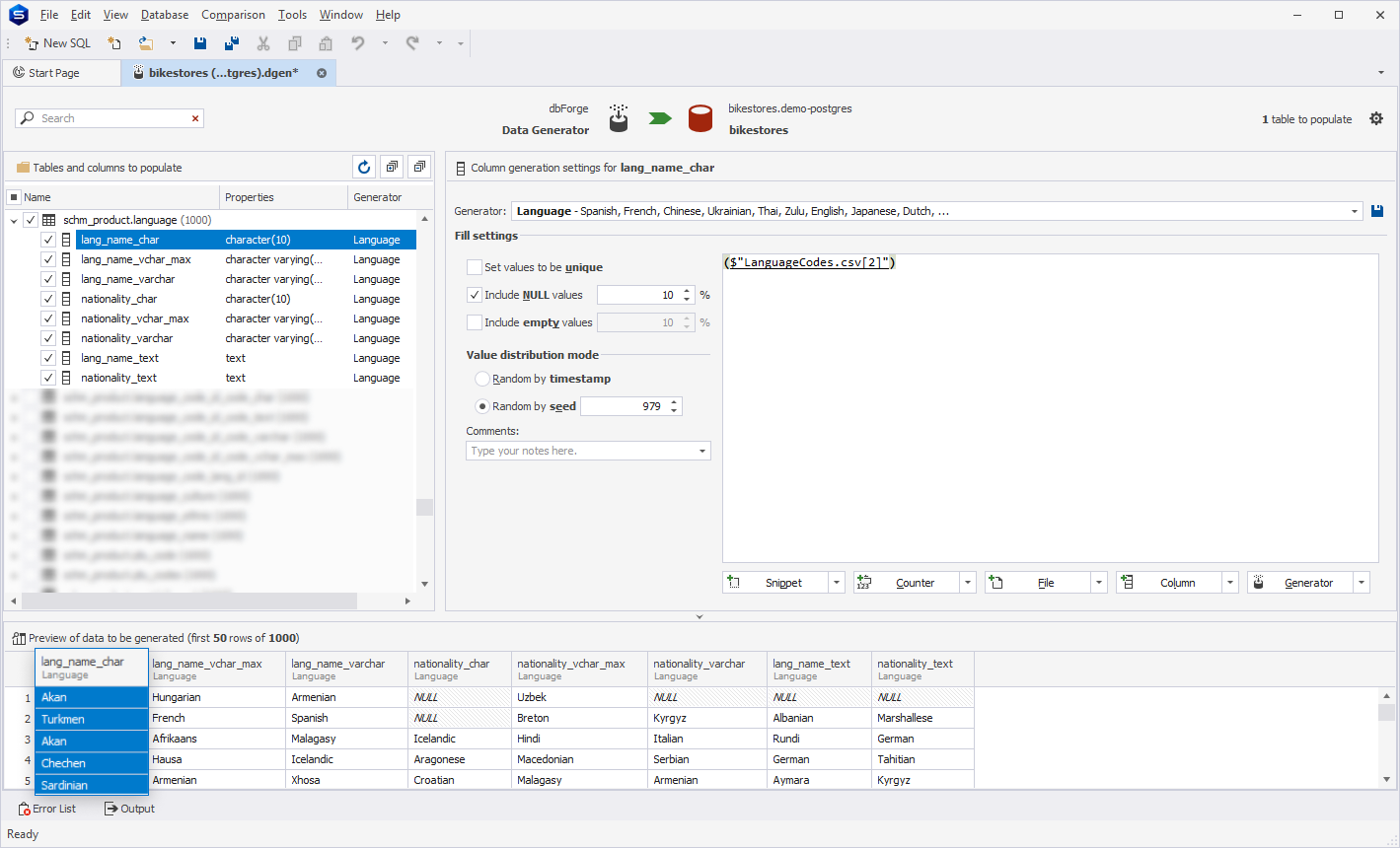
Language generator
The Language generator produces the full names of languages, used in multilingual systems, linguistic databases, or localization applications. It provides human-readable language identifiers based on predefined language standards.
Generator properties
The table provides key details about the generator, including the short name, sample of the generated data, the supported data types, and whether it is specific to a particular country.
| Short name | Example of generated data | Data type matching | Country-specific |
|---|---|---|---|
| Language | Spanish, French, Chinese, … | character varying character text |
Default |
Matching rules
The generator can be assigned to a column that matches any of the following rules:
- The column name starts with ‘Lang’ and ends with ‘Name’, with any or no characters in between, regardless of the table name.
- The column name is ‘nationality’ or ‘language’, regardless of the table name.
- The column name ends with ‘Name’, preceded by any or no characters, and it belongs to a table whose name is ‘Language’.
- The column name is ‘descr’, and it belongs to a table whose name is ‘ethnic’.
- The column name is ‘name’, and it belongs to a table whose name is ‘culture’.
Configure additional options
The generator produces data based on a regular expression. Since it is built on the RegExp generator, see Regular Expression generator to customize settings and understand the correct usage of syntax.
The Text box displays a .csv file that contains a list of language codes. The default path to the file is C:\Users\Public\Documents\Devart\dbForge Studio for PostgreSQL\Data Generators\LanguageCodes.csv[2].
Preview of the column data generated by the Language generator